比Deepseek还要Deep!起底GBDT做回归预测的秘密
决策树是机器学习中一类重要的算法。它本质是这样一种算法,即将由程序hard-coded的各种if-else逻辑,改写成为可以通过数据训练得到的模型,而该模型在效果上等价于硬编码的if-else逻辑。
1 2 3 4 5 | |
这样做的好处是,大大增强了算法的普适性:只要有标注数据,无须编码,都可以转换成为对应的决策树模型,条件越复杂,这种优越性就表现的越明显。此外,在决策树的训练过程中,也自然地考虑了数据分布的统计特征、加入了容错(只要数据标注是正确的)。
单细胞生物: 决策树¶
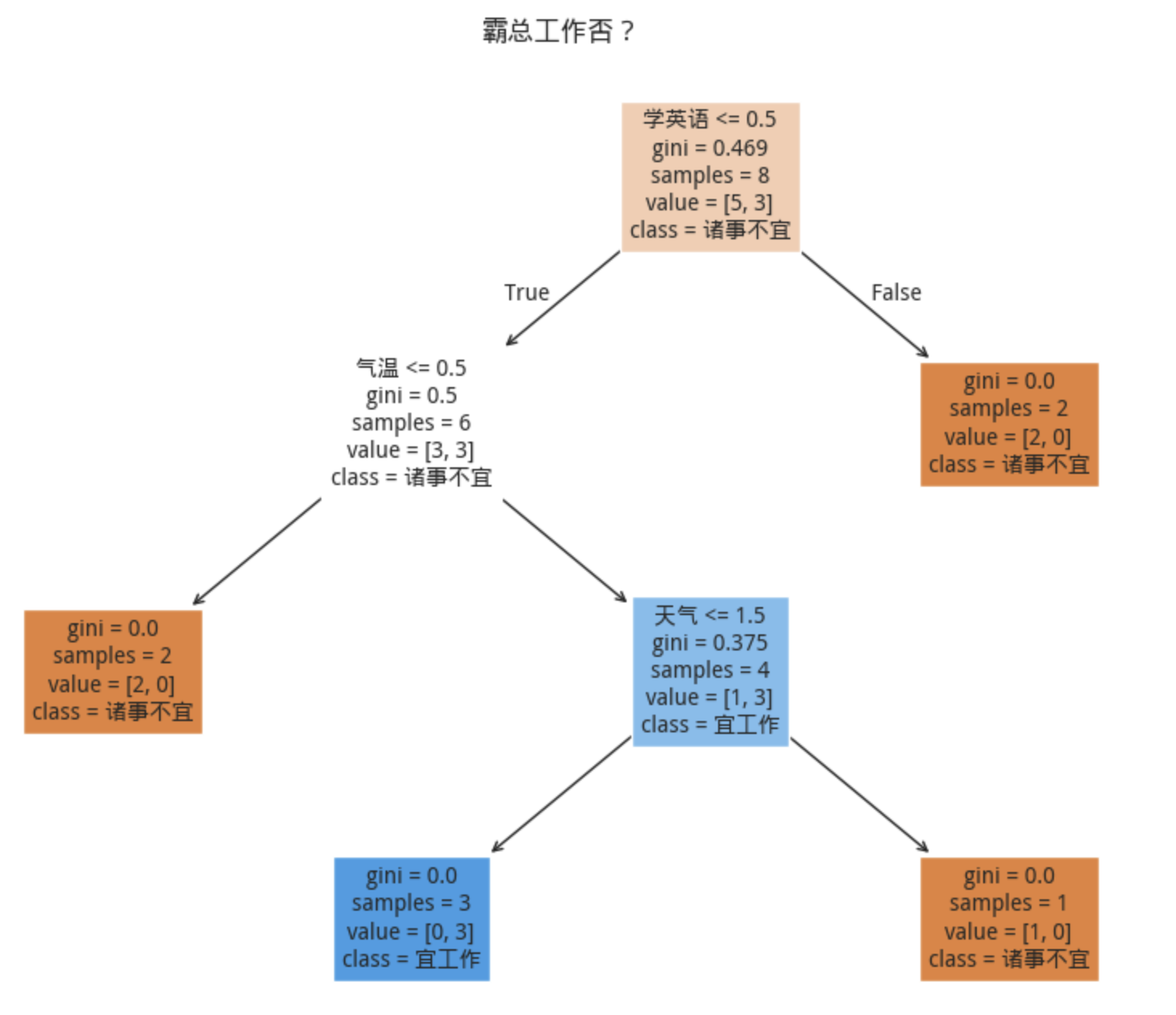
比如,假如我是霸总的助理,要根据他的生活习惯来安排明天是否工作。我收集到过往的数据如下:
1 2 3 4 5 6 7 8 | |
| 天气 | 气温 | 宜工作 | |
|---|---|---|---|
| 0 | 晴 | 高温 | 0 |
| 1 | 晴 | 高温 | 0 |
| 2 | 晴 | 舒适 | 1 |
| 3 | 晴 | 凉爽 | 1 |
| 4 | 阴 | 凉爽 | 1 |
| 5 | 阴 | 凉爽 | 1 |
| 6 | 雨 | 凉爽 | 0 |
| 7 | 雨 | 凉爽 | 0 |
我们就可以用决策树来训练一个模型,从而为他安排明天的出差。如果哪一天他与某个女艺人热恋了,这样会新增一个判断条件,如果头一天晚上学了英语,第二天就不工作了,这样我们就只需要改数据就行了。
1 2 3 4 5 6 7 8 9 | |
下面这个决策树模型简单是简单了点,不过,它涉及到了决策树模型构建的全部过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | |
增加¶
《因子投资与机器学习策略》喊你上课啦!
面向策略研究员的专业课程,涵盖因子挖掘、因子检验和基于机器学习的策略开发三大模块,构建你的个人竞争优势!
- 全网独家精讲 Alphalens 分析报告,助你精通因子检验和调优。
- 超 400 个独立因子,分类精讲底层逻辑,学完带走 350+ 因子实现。
- 课程核心价值观:Learning without thought is labor lost. Know-How & Know-Why.
- 三大实用模型,奠定未来研究框架1:聚类算法寻找配对交易标的(中性策略核心)、基于 XGBoost 的资产定价、趋势交易模型。
- 领先的教学手段:SBP(Slidev Based Presentation)、INI(In-place Notebook Interaction)和基于 Nbgrader(UCBerkley 使用中)的作业系统。
 课程助教: 宽粉
课程助教: 宽粉
1. 示例模型思路新颖。未来一段时间,你都可以围绕这些模型增加因子、优化参数,构建出领先的量化策略系统。