用HDBSCAN聚类算法选股是否有效
 前篇文章提到可以用HDBSCAN算法来来对资产进行聚类,在聚类完成之后,对聚类结果进行协整检验,通过计算对冲比,可以构造成平稳序列。我们知道一个平稳时间序列的均值、方差恒定并且有自协相关特性,那么,一旦它偏离了均值,迟早都会回归到均值上。利用这一点,可以生成交易信号。
前篇文章提到可以用HDBSCAN算法来来对资产进行聚类,在聚类完成之后,对聚类结果进行协整检验,通过计算对冲比,可以构造成平稳序列。我们知道一个平稳时间序列的均值、方差恒定并且有自协相关特性,那么,一旦它偏离了均值,迟早都会回归到均值上。利用这一点,可以生成交易信号。
那怎样证明HDBSCN算法对寻到协整对的交易策略是有效的呢?下面我们来一步步分析。
首先,从前面的文章我们知道了HDBSCN算法是一种基于密度的聚类算法,它通过计算每个样本的密度来确定样本的聚类类别。HDBSCN算法的优点是它可以自动确定聚类中心,并且可以处理高维数据。下面是用python代码来实现HDBSCN算法的关键代码,获取历史数据的时间是从2022年1月1日至2023年12月31日。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 | start_date = datetime.date(2022, 1, 1)
end_date = datetime.date(2023,12,31)
barss = load_bars(start_date, end_date, 2000) #获取历史资产数据,这里选取2000条数据
closes = barss["close"].unstack().ffill().dropna(axis=1, how='any') #处理缺失值,将close列的MultiIndex转换为DataFrame二维表格,并使用ffill()方法填充缺失值。
clusterer = hdbscan.HDBSCAN(min_cluster_size=3, min_samples=2)# 使用 HDBSCAN 进行聚类,python可以直接安装hdbscan包
cluster_labels = clusterer.fit_predict(closes.T) #转置是因为要对资产(特征)聚类
clustered = closes.T.copy()
clustered['cluster'] = cluster_labels# 将聚类结果添加到 DataFrame 中
clustered = clustered[clustered['cluster'] != -1] # 剔除类别为-1的点,这些是噪声,而不是一个类别
clustered_close = clustered.drop("cluster", axis=1)
unique_clusters = set(cluster_labels)
num_clusters = len(unique_clusters) # 获取有效的簇数量
print(f"有效的簇数量为:{num_clusters}")
tsne = TSNE(n_components=3, random_state=42)
tsne_results = tsne.fit_transform(clustered_close) # 使用t-SNE进行降维,便于后面的簇类可视化
reduced_tsne = pd.DataFrame(data=tsne_results, columns=['tsne_1', 'tsne_2', 'tsne_3'], index=clustered_close.index)# 将t-SNE结果添加到DataFrame中
reduced_tsne['cluster'] = clustered['cluster']
fig_tsne = px.scatter_3d(
reduced_tsne,
x='tsne_1', y='tsne_2', z='tsne_3',
color='cluster',
title='t-SNE Clustering of Stock Returns',
labels={'tsne_1': 't-SNE Component 1', 'tsne_2': 't-SNE Component 2'}
) #进行3D散点图可视化
fig_tsne.layout.width = 1200
fig_tsne.layout.height = 1100
fig_tsne.show()
|
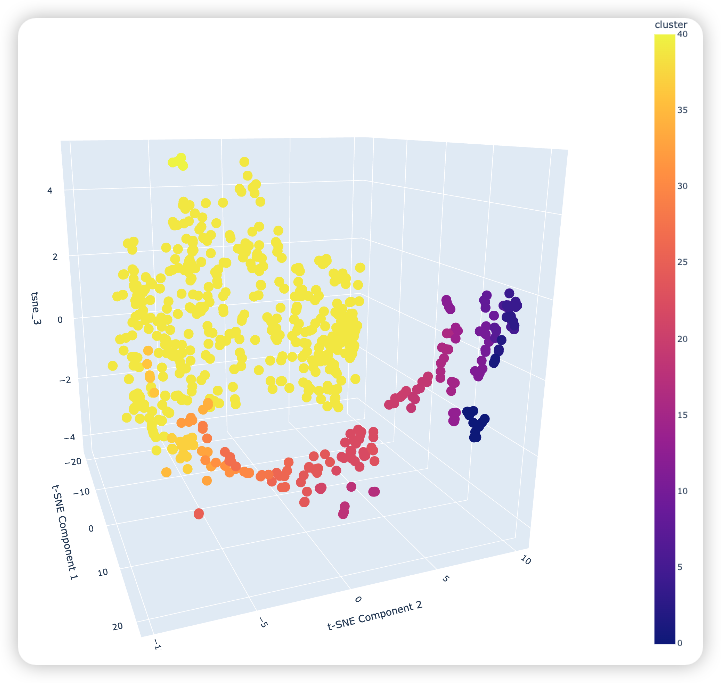
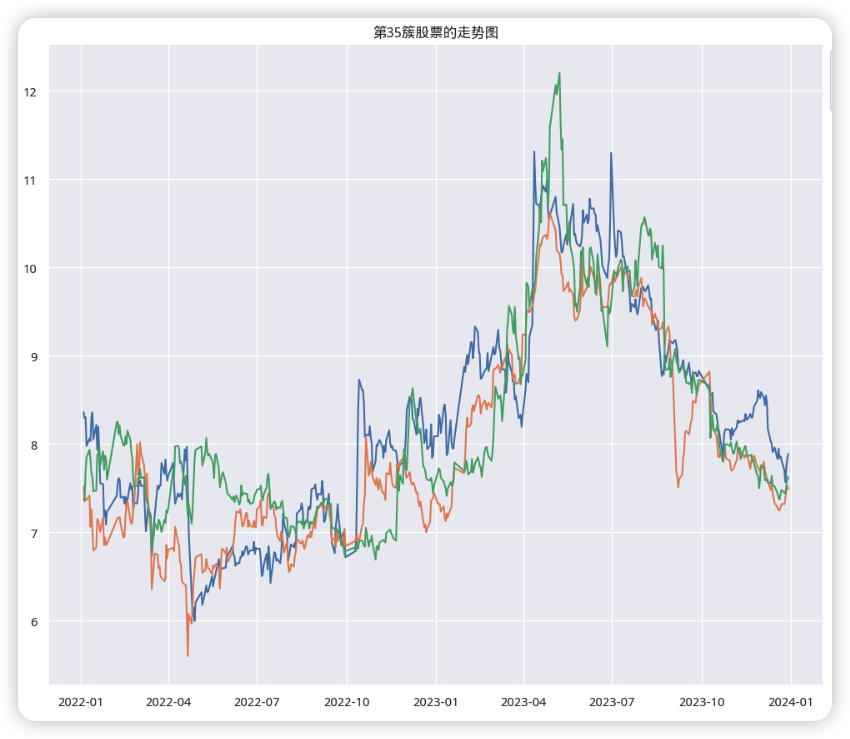
3D图展示的是股票的3D空间分布,不同颜色代表不同的聚类类别,从图中可以观察到,这期间的2000支股票被分成了40多个类,除了一个包含420支股票的第39簇,其它簇都少于20支股票。下面分析第35簇,里面有3支股票,从2022年10月1日左右三支股票都是持续上升的。
 那是否可以继续用HDBSCAN聚类算法对2022年10月份之前的数据进行聚类,看上面的3支股票是否也被分在了一起。还是上面的代码,只是将时间改为了2022年1月1日到2022年10月1日,运行后得到下面的3D图:
那是否可以继续用HDBSCAN聚类算法对2022年10月份之前的数据进行聚类,看上面的3支股票是否也被分在了一起。还是上面的代码,只是将时间改为了2022年1月1日到2022年10月1日,运行后得到下面的3D图:
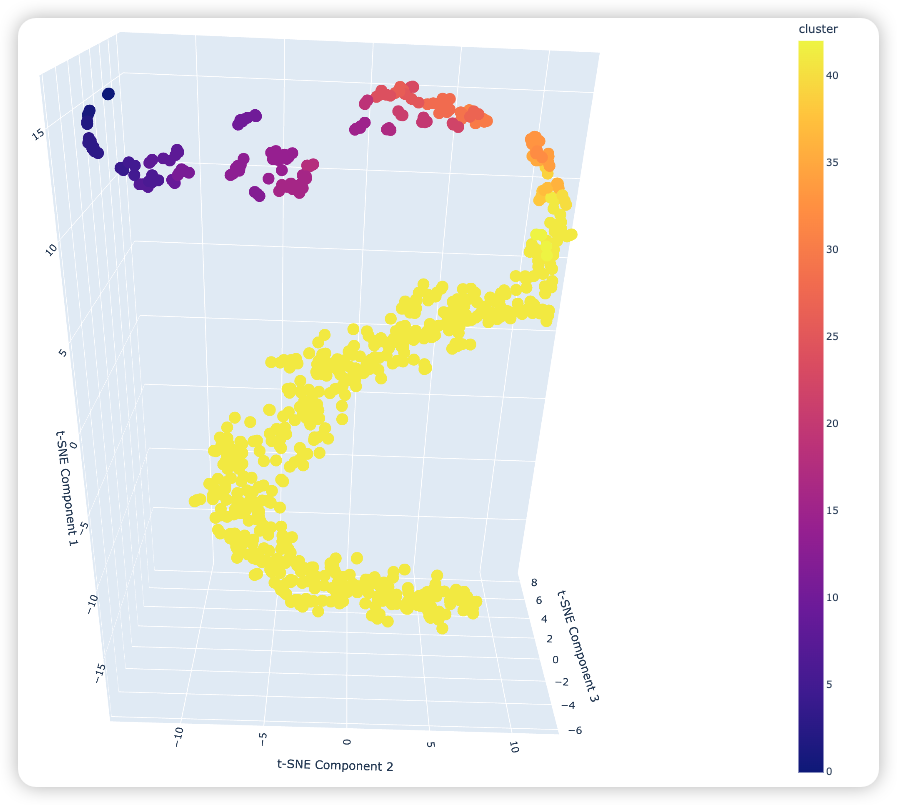
和上面的3D图相比,分为一类的股票(特征)更相似,所以聚集的更密集。那上面第35簇中的三支股票是否还是会被分为一类呢?可以将每一簇都都可视化展示出来(和前面文章一样的方法),观察那三支股票在这次分类的那一簇中。通过观察,我们发现这三支股票是被分在了一类,但是这一类里面有大概600支股票,我们看看这600多支股票的可视化结果:
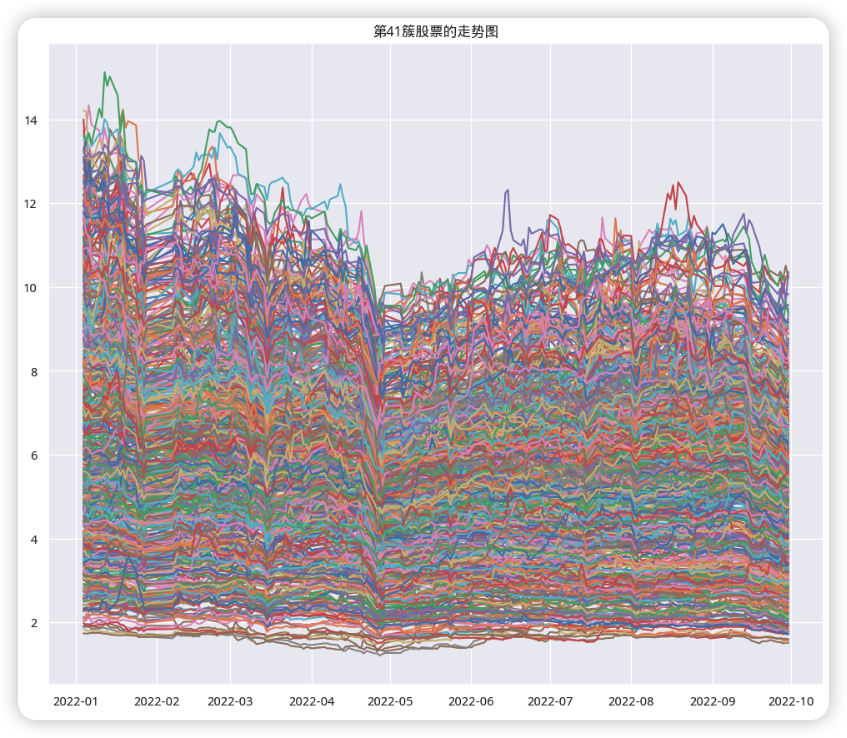 我们想要知道的是这三支股票在持续上升之前会有什么特征,虽然这一个大类里面的股票数据有点多,但观察上面的趋势图可以知道它们的走势大致是相同的,所以才会被分为一类。那继续将这600多支股票在用HDBSCA进行聚类,之前的3支股票会不会被分为一类?也就是说需要验证3支股票在持续上升前的大致趋势也是一致。感兴趣的读者可以自己尝试一下,下面是小编验证的结论:
对这600支股票重新在2022年1月到2022年10月进行聚类,总共被分成了三类,之前的那三支股票有2支被分在了一簇,另外一支在另一类里面。这个结果我认为足以说明这600支股票在2022年1月到2022年10月之间的趋势是相似的,所以600多支股票只被分为三类。
我们想要知道的是这三支股票在持续上升之前会有什么特征,虽然这一个大类里面的股票数据有点多,但观察上面的趋势图可以知道它们的走势大致是相同的,所以才会被分为一类。那继续将这600多支股票在用HDBSCA进行聚类,之前的3支股票会不会被分为一类?也就是说需要验证3支股票在持续上升前的大致趋势也是一致。感兴趣的读者可以自己尝试一下,下面是小编验证的结论:
对这600支股票重新在2022年1月到2022年10月进行聚类,总共被分成了三类,之前的那三支股票有2支被分在了一簇,另外一支在另一类里面。这个结果我认为足以说明这600支股票在2022年1月到2022年10月之间的趋势是相似的,所以600多支股票只被分为三类。
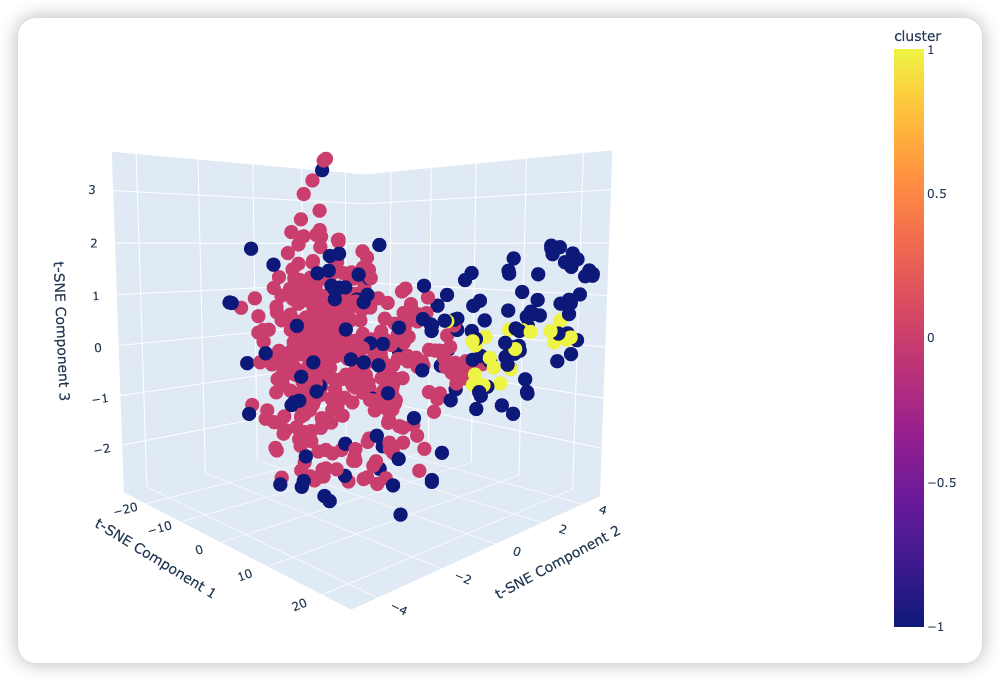 所以,HDBSCAN算法对选股是有效的,它选出来的一类趋势类似,所以可以用前一篇内容中构造这一类股票的平稳序列来产生交易信号。
所以,HDBSCAN算法对选股是有效的,它选出来的一类趋势类似,所以可以用前一篇内容中构造这一类股票的平稳序列来产生交易信号。