Pandas核心语法[1]
Pandas在量化交易中,处于核心地位。许多基于Python SDK的数据源返回的数据格式一般是pandas.DataFrame。因子分析库Alphalens、性能评估库empyrical等都依赖于Pandas。
这并不奇怪。因为Pandas的开发者Wes McKinney原本是资管公司AQR Capital Management的研究员。他在处理大量金融分析任务时,发现Python的现有工具(如NumPy)无法高效处理结构化数据分析,于是在2008年开始开发Pandas,并于2009年将其开源。
1.1. 基本数据结构¶
Pandas 的核心数据结构是 Series(类似于一维数组)和 DataFrame(矩形的数据表)数据结构。
1.2. Series¶
Series 由一组数据以及一组与之相关的数据标签(即索引)组成。仅由一个数组即可创建最简单的Series。Series以交互式的方法呈现,索引位于左边,值位于右边(一般会自动创建一个从 0 到 N-1 的索引,这里的 N 为数据长度)。与Numpy数组相比,我们可以通过索引的标签选取Series中的单个或一组值。还可以将其看作长度固定的有序字典,在可能使用字典的场景中,也可以使用 Series。对于许多应用而言,Series 最实用的一个功能是它在算术运算中能自动对齐索引标签。
1 | |
1.2.1. 由数组简单创建(默认索引)¶
1 2 | |

通过 pd.Series() 直接转换 Python 列表,默认生成从 0 开始的整数索引。
1.2.2. 由字典创建(自定义索引)¶
字典的键自动转为索引,值转为数据:
1 2 | |

通过to_dict的方法,Series也能转换回字典:
1 | |
1.2.3. 自定义索引¶
通过 index 参数指定任意不可变对象作为索引:
1 2 | |

1.2.4. 创建带时间戳索引的Series¶
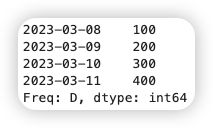
生成时间序列数据:
1 2 | |
1.2.5. 查询数组值和索引对象¶
可以通过Series的array和index属性获取其数组值和索引对象:
1 2 3 | |
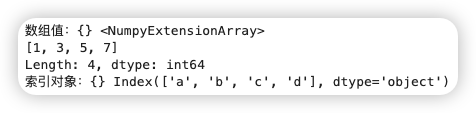
与Numpy数组相比,可以通过索引的标签选取Series中的单个或一组值:
1 | |
1 2 3 4 5 6 7 8 | |
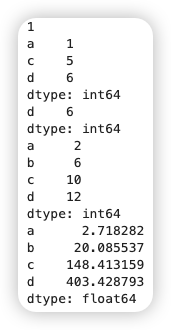
构建Series和Pandas时,所用到的任何数组或其他标签序列都会转换为索引对象:
1 2 3 4 5 6 7 | |
由于Index对象的不可变性,可以使索引对象在多个数据结构之前安全共享:
1 2 3 4 5 | |
下面总结一下常用的索引的方法和属性:
| 方法/属性 | 描述 | 示例 |
|---|---|---|
append |
连接额外的索引对象,生成一个新的索引。 | new_index = index1.append(index2) |
diff |
计算索引的差集。 | diff_index = index1.diff(index2) |
intersection |
计算索引的交集。 | common_index = index1.intersection(index2) |
union |
计算索引的并集。 | union_index = index1.union(index2) |
isin |
返回一个布尔数组,表示每个值是否包含在传递的集合中。 | bool_array = index.isin(['a', 'b']) |
delete |
删除指定位置的元素,返回新的索引。 | new_index = index.delete(0) |
drop |
删除传递的值,返回新的索引。 | new_index = index.drop('a') |
insert |
在指定位置插入元素,返回新的索引。 | new_index = index.insert(1, 'new_value') |
is_monotonic |
返回 True,如果索引是单调递增或递减的。 |
is_monotonic = index.is_monotonic |
is_unique |
返回 True,如果索引没有重复的值。 |
is_unique = index.is_unique |
| 方法/属性 | 描述 | 示例 |
|---|---|---|
unique |
返回索引的唯一值数组。 | unique_values = index.unique() |
reindex |
根据新索引重新排列数据,缺失值用 NaN 填充。 |
new_series = series.reindex(new_index) |
reset_index |
重置索引为默认整数索引,原索引变为列。 | df_reset = df.reset_index() |
set_index |
将某一列设置为索引。 | df.set_index('column_name', inplace=True) |
sort_values |
对索引进行排序。 | sorted_index = index.sort_values() |
to_series |
将索引转换为 Series。 |
index_series = index.to_series() |
values |
返回索引的 NumPy 数组。 | index_values = index.values |
name |
获取或设置索引的名称。 | index_name = index.name |
shape |
返回索引的形状(长度)。 | index_shape = index.shape |
size |
返回索引的长度。 | index_size = index.size |
以下是一个与金融量化相关的代码示例,展示了如何使用 Pandas 计算股票的移动平均线(MA)和相对强弱指数(RSI):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
1 2 3 4 5 6 7 8 9 | |