Pandas核心语法[3]
“DataFrame 是 Pandas 的核心数据结构,支持多种数据类型和灵活的操作方式。无论是嵌套字典、NumPy 数组还是 CSV 文件,都可以轻松转换为 DataFrame,助你快速完成数据分析任务。”
1. 快速探索 DataFrame¶
1.1. 创建 DataFrame¶
DataFrame 含有一组有序且有命名的列,每一列可以是不同的数据类型(数值、字符串、布尔值等)。DataFrame 既有行索引也有列索引,可以看作由共用同一个索引的Series组成的字典。虽然DataFrame是二维的,但利用层次化索引,仍然可以用其表示更高维度的表格型数据。如果你使用的是Jupyter notebook,pandas的DataFrame 对象将会展示为对浏览器更为友好的HTML表格。
1.1.1. 传入一个由等长列表或Numpy数组构成的字典¶
1 2 3 4 5 6 | |
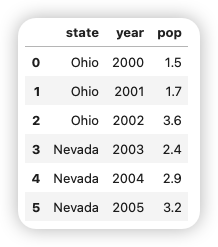
生成的DataFrame会自动加上索引(和Series一样),且全部列会按照data键(键的顺序取决于在字典中插入的顺序)的顺序有序排列。 (如果你使用的是Jupyter notebook,pandas的DataFrame对象会展示为对浏览器更为友好的HTML表格)
对于特别大的DataFrame,可以使用head方法,只展示前5行。相似地,tail方法会返回最后5行。
1 2 | |
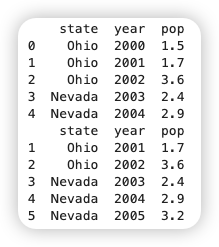
下面还有几种创建DataFrame的情况:
1 2 3 4 5 | |
1.1.2. 传入嵌套字典¶
如果将嵌套字典传给DataFrame,pandas就会将外层字典的键解释为列,将内层字典的键解释为行索引。
1 2 3 | |
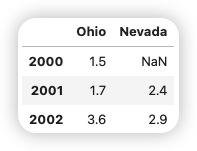
使用类似于Numpy数组的方法,可以对 DataFrame 进行转置(交换行和列):
1 | |
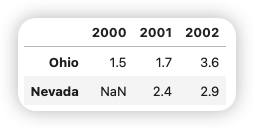
内层字典的键被合并后形成了结果的索引。如果明确指定了索引,则不会这样:
1 | |
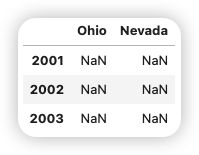
由Series组成的字典差不多也是一样的用法:
1 2 | |
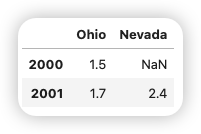
可以向DataFrame构造器输入的数据:
| 类型 | 说明 |
|---|---|
| 字典 (Dict) | 键为列名,值为列表、NumPy 数组或 Series。每列的长度必须一致。 |
| 列表 (List) | 列表中的每个元素是一个字典,字典的键为列名,值为对应列的数据。 |
| NumPy 数组 | 二维数组,每行对应 DataFrame 的一行,每列对应 DataFrame 的一列。 |
| Series | 单个 Series 可以构造单列的 DataFrame,多个 Series 可以构造多列。 |
| 结构化数组 | NumPy 的结构化数组,字段名对应 DataFrame 的列名。 |
| 其他 DataFrame | 可以通过复制另一个 DataFrame 来创建新的 DataFrame。 |
| CSV 文件 | 通过 pd.read_csv() 读取 CSV 文件并转换为 DataFrame。 |
| Excel 文件 | 通过 pd.read_excel() 读取 Excel 文件并转换为 DataFrame。 |
| JSON 数据 | 通过 pd.read_json() 读取 JSON 数据并转换为 DataFrame。 |
| SQL 查询结果 | 通过 pd.read_sql() 读取 SQL 查询结果并转换为 DataFrame。 |
| HTML 表格 | 通过 pd.read_html() 从 HTML 页面中提取表格并转换为 DataFrame。 |
| 剪贴板数据 | 通过 pd.read_clipboard() 从剪贴板中读取数据并转换为 DataFrame。 |
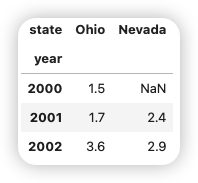
如果设置了DataFrame的index和columns的name属性,则这些信息也会显示出来:
1 2 3 | |
1 2 3 4 5 | |

1.2. DataFrame 的合并和连接¶
在 Pandas 中,concat、join 和 merge 是用于合并和连接 DataFrame 的三种主要方法。它们各有不同的用途和适用场景,以下是详细说明。
1.2.1. concat:基于轴的数据拼接¶
concat 主要用于沿指定轴(行或列)将多个 DataFrame 或 Series 拼接在一起。
参数说明: - objs:需要拼接的 DataFrame 或 Series 列表。 - axis:拼接方向,0 表示按行拼接(默认),1 表示按列拼接。 - join:拼接方式,'outer'(默认,保留所有索引)或 'inner'(仅保留共同索引)。 - ignore_index:是否忽略原索引并生成新索引,默认为 False。 - keys:为拼接后的数据添加层次化索引。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 | |
适用场景: - 将多个结构相似的数据集简单堆叠在一起。 - 不需要基于键值匹配,只需按行或列拼接。
1.2.2. merge:基于键值的合并¶
merge 用于根据一个或多个键将两个 DataFrame 合并在一起,类似于 SQL 中的 JOIN 操作。
参数说明: - left:左侧的 DataFrame。 - right:右侧的 DataFrame。 - how:合并方式,可选 'inner'(默认,内连接)、'left'(左连接)、'right'(右连接)、'outer'(外连接)。 - on:用于合并的列名(键),必须在两个 DataFrame 中都存在。 - left_on/right_on:当两个 DataFrame 的键列名不同时,分别指定左侧和右侧的键列。 - suffixes:当两个 DataFrame 中存在重复列名时,用于区分的后缀。
示例:
1 2 3 4 5 6 7 8 9 | |
适用场景: - 需要根据某些列(键)将两个表关联。 - 类似于 SQL 中的 JOIN,适合处理结构化数据。
1.2.3. join:基于索引的合并¶
join 是基于索引将两个 DataFrame 合并在一起,是 merge 的简化版。 参数说明: - other:要连接的另一个 DataFrame。 - on:用于连接的列名或索引。 - how:连接方式,可选 'left'(默认,左连接)、'right'(右连接)、'outer'(外连接)、'inner'(内连接)。 - lsuffix/rsuffix:当两个 DataFrame 中存在重复列名时,分别指定左侧和右侧的后缀。
示例:
1 2 3 4 5 6 | |
适用场景: - 基于索引进行简单的数据合并。 - 适合处理索引对齐的数据。
| 方法 | 主要用途 | 适用场景 | 灵活性 | 性能 |
|---|---|---|---|---|
| concat | 基于轴的数据拼接 | 简单堆叠数据,结构相似的数据集 | 按行或列拼接 | 适合大规模数据 |
| merge | 基于键值的合并,类似于 SQL 的 JOIN | 结构化数据,需要关联表 | 支持多种连接方式 | 适合小规模数据 |
| join | 基于索引的合并 | 索引对齐的数据 | 简化版 merge | 适合简单操作 |
1.3. 删除行和列¶
关键字del可以像在字典中那样删除列。
1 2 3 4 5 | |
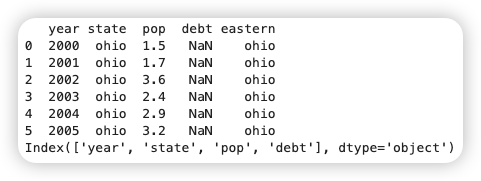
1.1.4. 定位、读取和修改¶
1.1.4.1. 获取列¶
通过类似于字典标记或点属性的方式,可以将DataFrame的列获取为一个Series。
1 2 | |
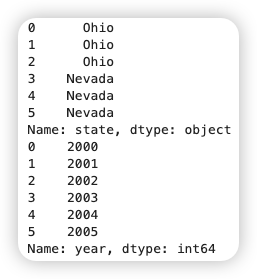
如果列名包含空格或下划线以外的符号,是不能用点属性的方式访问的。
1.1.4.2. 修改列¶
1 2 3 4 5 6 7 8 9 10 11 | |
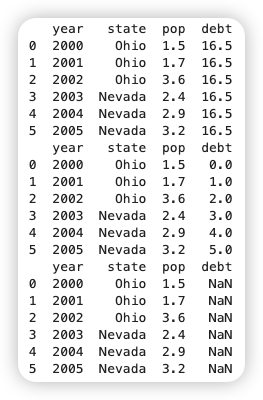
1.1.4.2. 获取行(iloc和loc)¶
通过iloc和loc属性,也可以通过位置或名称的方式进行获取行。
1 2 | |

1.1.5. 转置¶
转置操作是将 DataFrame 的行和列进行互换,即将行变为列,列变为行。Pandas 提供了两种方法来实现转置: - T 属性:直接调用 DataFrame.T 进行转置。 - transpose() 方法:通过 DataFrame.transpose() 实现转置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
注意事项: - 转置操作会改变 DataFrame 的结构,但不会修改原始数据。 - 如果 DataFrame 包含混合数据类型,转置后可能需要重新调整数据类型。
1.1.6. 重采样(resample)¶
重采样是将时间序列数据从一个频率转换为另一个频率的过程。Pandas 提供了 resample() 方法来实现重采样,支持以下两种类型: - 上采样(Upsampling):将低频数据转换为高频数据(如将日数据转换为小时数据)。 - 下采样(Downsampling):将高频数据转换为低频数据(如将分钟数据转换为小时数据)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
注意事项:
- 重采样需要 DataFrame 的索引为时间类型。
- 可以使用 fillna() 或 interpolate() 方法处理缺失值。