08 代码版本管理
Table of Content
1. 版本控制的意义¶
作者还在研究生阶段时,犯过一个刻骨铭心的错误:那是夜里两点,在 6 个小时之后,我们研发的系统就要在某个会议室里,交付给近 20 名使用者使用,而这些人将使用我们的软件,判定近 1 万青年人的前途。就在这个时候,我们发现之前通过了测试、已经打包好的版本,在清理磁盘空间时被删除了;但在那个版本之后,我们又改动了一些代码。这些改动包含了功能增强、小 bug 的修复,大约是一天多的工作量,未经测试,不能发布。
今天的程序员很难理解这为什么会是一个大问题。但在当时,由于缺乏版本管理工具(cvs 推出没有几年,还刚刚进入国内,在校园里的我们不了解也是情有可原),我们面临十分尴尬的局面:既没有现成可发布的软件,也没有一种办法能轻易地让代码回滚到通过测试的那个版本,从而构建出一模一样的版本。
那是一个痛苦的夜晚。一些人开始准备善后方案,我们则带着愧疚的心情,努力试图让代码尽可能地回滚到通过测试的那个版本的状态。
如果有 CI/CD,这种失误几乎不可能发生。如果有版本控制的话,即使发生了这种失误,纠错代价也会小很多。
版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。在本书写作时,作者就使用了版本控制,包括正文内容和附带源码。
如果你是一名图形或网页设计师,可能会需要保存某一幅图片或页面布局文件的所有修订版本(这或许是你非常渴望拥有的功能),采用版本控制系统(VCS)是个明智的选择。有了它你就可以将选定的文件恢复到之前的状态,甚至将整个项目都回退到过去某个时间点的状态,你可以比较文件的变化细节,查出最后是谁修改了哪个地方,从而找出导致怪异问题出现的原因,又是谁在何时导致了某个功能缺陷等等。使用版本控制系统通常还意味着,就算你乱来一气把整个项目中的文件改的改删的删,你也照样可以轻松恢复到原先的样子,但额外增加的工作量却微乎其微。
回到我读研的那个年代,许多人习惯用复制整个项目目录的方式来保存不同的版本,或许还会在目录名上加上备份时间以示区别。这么做唯一的好处就是简单,但是特别容易犯错。有时候会混淆所在的工作目录,一不小心会写错文件或者覆盖意想外的文件。
为了解决这个问题,人们很久以前就开发了许多种本地版本控制系统,大多都是采用某种简单的数据库来记录文件的历次更新差异。在这个时期最流行的版本控制系统可能是 RCS。其工作原理是在硬盘上保存补丁集(补丁是指文件修订前后的变化);通过应用所有的补丁,可以重新计算出各个版本的文件内容。
RCS 的缺点是它不支持分支操作(我们后面详细介绍什么是分支操作),加上它只能管理本地文件,无法支持多人协作。因此又发展 C/S 架构的集中化版本控制系统 (Centralized Version Control Systems,简称 CVCS),比如 CVS, subversion 以及 perforce。这些系统的基本原理是,有一个单独的服务器充当集中式的文件存储和版本库,所有的文件都必须通过这台服务器来访问,这样就可以有效地控制谁可以干什么事情。CVCS 的缺点是必须联网才能工作,如果在局域网环境下搭建服务器,还需要一台 24 小时开机的电脑作为服务器,而且所有的文件都必须通过这台服务器来访问,这样就会造成访问速度的瓶颈。
为了解决这些问题,人们又开发了分布式版本控制系统 (Distributed Version Control Systems,简称 DVCS)。比如 Git,Mercurial,Bazaar 等。DVCS 的基本原理是,每个开发者的电脑上都是一个完整的版本库。当开发者克隆了某个项目后,就拥有了这个项目的完整历史版本。如果在本地作了一些修改,想要与其他人分享,只需要把本地的版本库推送到服务器上即可。此后,其他人就可以从服务器上抓取最新的版本到本地,然后与自己的修改进行合并,再推送到服务器上。这就形成了一个分布式的协作开发模式。
在本书中,我们只介绍 Git 这一种版本控制系统。
2. 版本管理工具 Git¶
Git 诞生于 2005 年,它的开发者 Linus Torvalds 同时也是 Linux 操作系统的缔造者。它性能优越,适合管理大项目,有着令人难以置信的非线性分支管理系统,是目前世界上最流行的代码管理系统之一。
Git 在接口上基本延续了大多数版本控制系统的概念和 API,但在底层设计上却风格迥异,从而成就了它强大的引擎。它的主要特点是:
-
直接记录快照,而非差异比较:其他版本控制系统将不同版本之间的差异提取为增量进行记录,当要提取最新文件时,需要从最初始的版本开始,把到最新的版本之间的所有差异一路合并起来。早期计算机存储资源比较宝贵,因此前几代的版本控制系统采用这种设计,可以减少对存储资源的占用。Git 则反其道而行之,它把文件当作是对特定文件某一时刻的快照。每次你提交更新,或者保存项目的当前状态,Git 都会对当时的全部文件制作一个快照并保存这个快照的索引。Git 的这种设计使得 Git 非常适合处理大型项目,而且速度非常快。
-
几乎所有的操作都是本地执行:Git 的设计目标之一就是保证速度。Git 的主要操作都只需要访问本地文件和资源,几乎所有的信息都可以在本地找到,所以 Git 非常快。Git 的另一个设计目标是能够可靠地处理各种非线性的开发(分支)历史。Git 的分支和合并操作非常高效。
-
Git 的完整性保证: Git 中的所有数据在存储前都计算校验和,然后以校验和来引用。这意味着,Git 在存储和传输数据时,会自动发现数据的损坏。
-
追加式操作:你执行的 Git 操作,几乎只往 Git 数据库中添加数据。也就是说 Git 几乎不会执行任何可能导致文件不可恢复的操作。这使得我们使用 Git 成为一个安心愉悦的过程,因为我们深知可以尽情做各种尝试,而没有把事情弄糟的危险。
接下来,我们将主要按照 git 的使用场景顺序,由浅入深地介绍 git 命令与技巧。
2.1. 创建 git 仓库¶
Git 仓库(有人也称作存储库)是项目的虚拟存储。它允许您保存代码的版本,您可以在需要时访问这些版本。
通常,我们有两种方式来创建 git 仓库,取决于你的开发工作是如何开始的。不过,在正式介绍之前,我们先看一个最基础的设置命令。
当你在某台机器上(或者某个工程中)初始使用 git 时,我们需要做的第一件事就是设置你的用户名和邮箱地址。这些信息在每次提交时都会用到。
1 2 | |
这里我们使用了--global 选项,如此一来,在同一台机器上仅需配置一次,所有的项目都将复用这个设置。但如果你同时为多个项目工作,并且希望在不同的项目中,使用不同的用户名和邮箱地址的话,就不要使用这一选项。其结果是,这些配置将会被写入到当前项目的.git/config 文件中,而不会影响到其它工程。当然,这种按项目的配置,就必须等到项目仓库设置完成之后才能进行。
现在,让我们创建一个本地仓库。
2.1.1. 创建新的本地仓库:git init¶
要创建新的存储库,您将使用 git init 命令。git init 是您在新存储库的初始设置期间使用的一次性命令。执行此命令时,git 将在您当前的工作目录中创建一个新的子目录。这也将创建一个新的主分支。
此示例假设您已经有了一个现存的项目文件夹,希望把它加入的 git 的版本控制。我们需要先进入该项目的根目录,再运行 git init 命令。
1 2 | |
2.1.2. 克隆现有存储库:git clone¶
如果项目已经在中央存储库中建立起来,克隆命令是我们获取版本的最常用方式。
假设 Github 是我们的服务器,我们需要把本书在 Github 上的仓库克隆到本地:
1 | |
除了上述方式还,我们还可以使用 https 协议来克隆:
1 | |
1 | |
2.2. 建立与远程仓库的关联:git remote¶
如果本地仓库是通过 git clone 建立起来的,那么它就已经和远程仓库建立了关联。如果是通过 git init 建立起来的,我们还需要通过 git remote 命令来建立这种关联,以便后续我们可以将本地的改动,推送到远程服务器上。
如果你是为该项目第一个创建仓库的人,那么很可能你还得登录到服务器上,创建一个空的中央仓库。如果你是一个团队的一员,那么你可能已经有了一个中央仓库,你需要知道它的 URL。
象 Github, gitlab,或者 bitbucket 这些代码托管平台,都提供了 web 界面,我们可以登录到 web 界面上进行操作。
如果我们使用的托管平台是 github,还可以使用它的命令行工具 Github CLI 来进行操作。以下命令将在 github 上创建一个公开的仓库,名字为 sample。在很多场合下,这个名字也被称为 project_slug。
1 | |
现在,既然已经有了远程仓库,也得到了它的 URL,我们可以来建立本地与远程之间的关联了:
1 2 3 | |
这个命令还为远程仓库定义了一个别名,即 origin。这个别名可以是任意的,比如,既然我们的服务器使用了 github,我们也可以将别名声称为 github。不过 origin 是 git 默认的别名,因此,多数人一般都使用这个别名。定义了别名之后,我们就可以在其它命令中使用别名来代替远程仓库的地址,从而可以使命令变简洁。
2.3. 保存更改:add, commit, stash 等¶
当我们修改了工作区的一些文件(包括新建文件、修改文件内容和删除文件)时,我们需要保存这种更改到版本控制系统,或者暂时贮藏起来。这就需要 add, commit 和 stash 等命令。
1 2 3 4 5 | |
1 | |
Info
从 2022 年 10 月 1 日起,github 上创建的新的代码仓库,默认分支都是 main,而不是之前的 master。上述更名操作,正是为了保持与 github 的一致性。
github 将默认分支名从 master 改为 main,主要是受 2020 年 6 月美国的"Black Lives Matter"运动的影响。这个运动的目的是为了反对种族歧视,而 master 这个词,正是从奴隶主的角度来命名的,因此,将其改名为 main,是为了避免这种歧视。
受"Black Lives Matter"影响,除了 github, 许多科技巨头或知名软件也都调整了自己的业务或者产品。比如,MySQL 宣布删除 master、黑名单、白名单等术语;Linus Torvalds 通过了 Linux 中避免 master/slave 等术语的提案;还有 Twitter 、GitHub、微软、LinkedIn、Ansible、Splunk、OpenZFS、OpenSSL、JP Morgan、 Android 移动操作系统、Go 编程语言、PHPUnit 和 Curl 等宣布要对此类术语进行删除或更改。
实际上,计算机术语的政治正确性早已不是新鲜话题。2004 年,“master/slave” 曾被全球语言检测机构评为年度最不政治正确的十大词汇之一。2018 年,IETF 也在草案当中指出,要求开源软件更改 “master/slave” 和 “blacklist/whitelist” 两项表述。如果我们的软件是面向全球的,那么我们应该尽量避免使用这些术语,以免造成不必要的误解。
您已经注意到,我们将变更保存到 git 系统中的步骤不止一步。实际上,git 中的很多操作都是多阶段的,常常会经历一个修改(modified)、暂存(stagged),提交(committed)和推送(push)的过程。要理解这几个阶段,我们还得先深入介绍一下相关的三个基本概念:HEAD, index 和 working tree。
头(HEAD)
HEAD 是当前分支引用的指针,它总是指向该分支上的最后一次提交。同时也是下一次提交的父结点。在某些场景下,我们也可以把 HEAD 看作是分支的代名词。它是我们执行 git commit 命令后,变更要去往的地方。
索引(index)
当我们调用 git add 命令时,我们就会把变更记录到索引区。然后再从这里把变更提交到分支。更多时候,人们会用暂存区这个词,但 index 是 Git 中使用的规范术语。
工作目录(working tree)
最后,我们得有自己的工作目录(通常也叫工作区)。另外两棵树(即 HEAD 和 INDEX)会以一种高效但并不直观的方式,将它们的内容存储在.git 文件夹中。而工作目录会将它们解包为实际的文件以便编辑。你可以把工作目录当做沙盒。在你将修改提交到暂存区并记录到历史之前,可以随意更改。
下图则展示了这三个概念的关系:
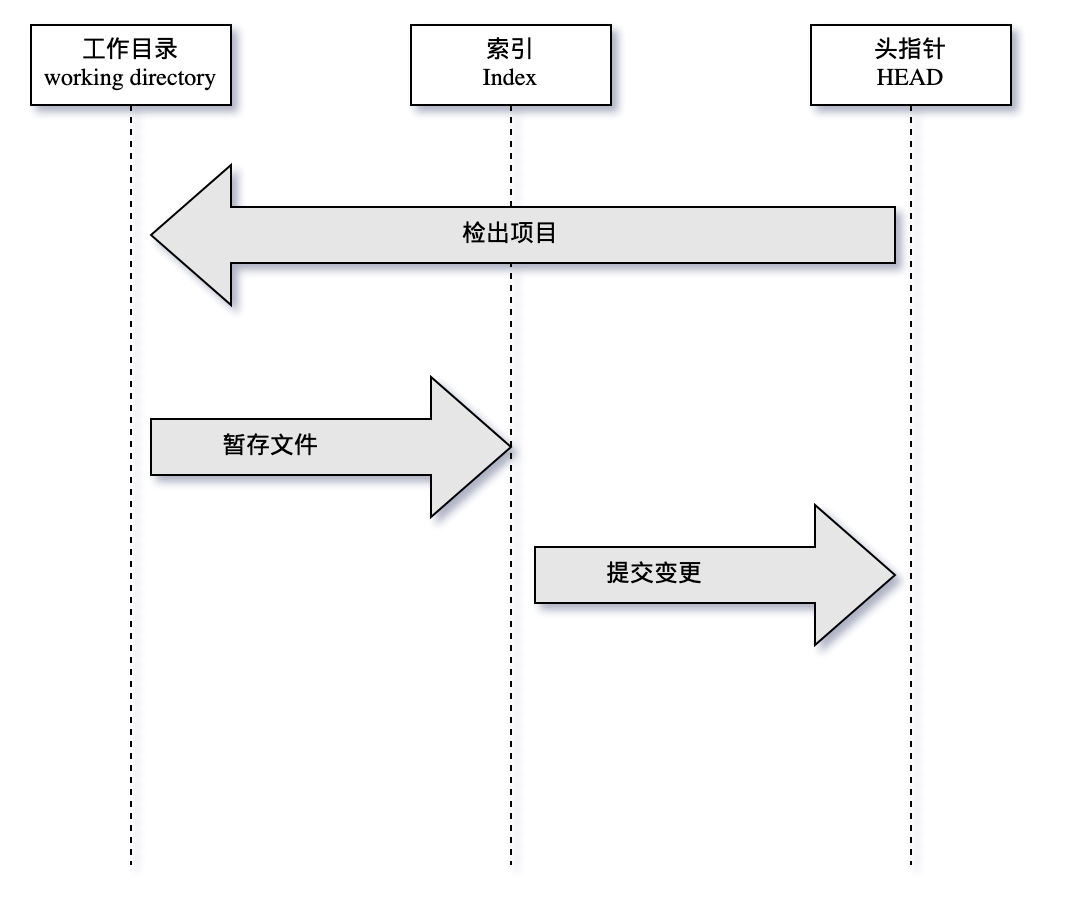
我们结合命令和图示来解释变更的流动。
1 2 3 4 5 6 7 8 9 10 11 | |
此时在 vscode 侧面板上,我们可以看到 README.md 文件出现在 changes 类别下(注意 vscode 使用的术语与 git 不同,这是可以理解的),
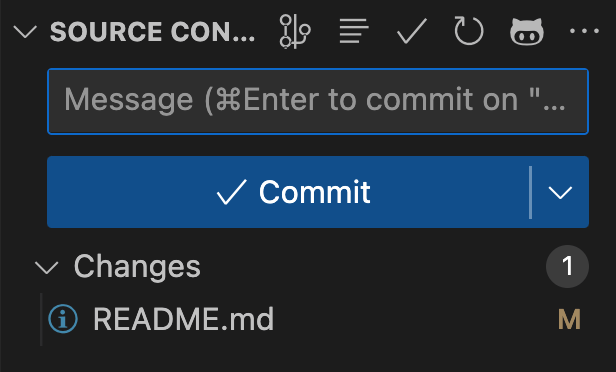
我们可以通过 git add 命令将 README.md 文件添加到暂存区,然后再次查看状态:
1 2 3 4 5 6 7 8 9 | |
Status 命令提示 README.md 还没有提交(此时文件处在暂存区 staging area 中)。此时在 vscode 侧面板上,我们可以看到 README.md 文件出现在 Staged Changes 类别下,如下图所示:
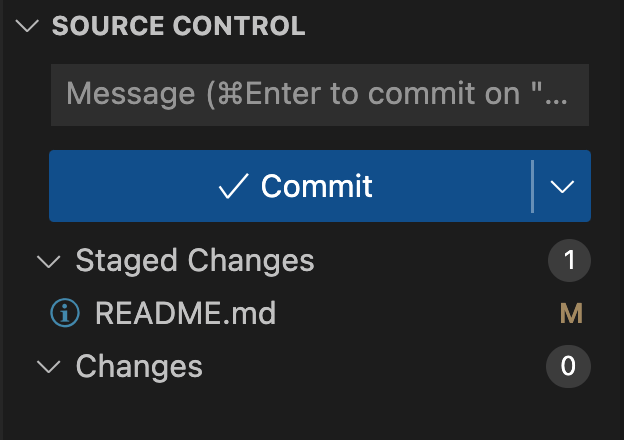
接下来,我们提交到本地仓库,并再次查看当前状态:
1 2 3 4 5 6 7 8 | |
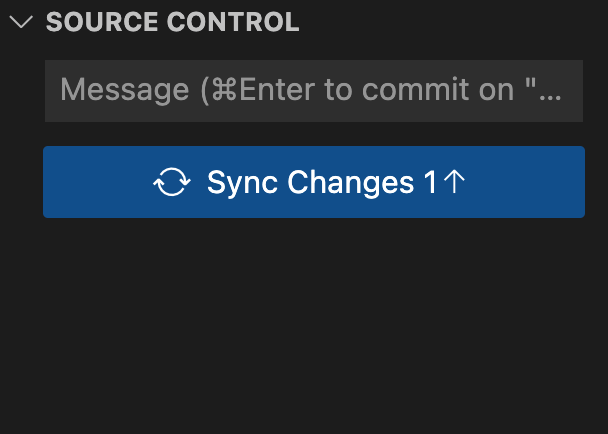
现在,三个区域的状态完全一致(见上面输出中的最后一句:nothing to commit, working tree clean)。但还有一条提示:本地分支领先远程 main 分支一个提交(Your branch is ahead of ‘origin/main’ by 1 commit),即我们刚刚提交的变更还没同步到远程服务器。此时,我们刚刚执行的提交将可以在 COMMITS 类别下找到。
如下图所示,此时在 vscode 侧面板上,SOURCE CONTROL 类别下已清空,只出现了一个 sync changes 的按键,一旦我们点击此按钮,我们刚刚提交的变更就会发布到远程服务器上。
这种情况下,我们就需要用到 stash 命令。我们先介绍 git stash 命令行模式的一些例子,然后再介绍如何从图形界面来使用它:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
在 vscode 的 git lens 扩展中,我们可以在"Changes"面板中,将当前的变更贮藏(如图 8- 5 所示):
上图中红色框内的按钮即是 stash all 按钮。我们点击它,就可以将当前的变更贮藏起来了。我们可以在"Stashes"面板中,查看所有的贮藏:
点击"Apply"按钮,在弹出来的对话框中,给我们两个提示,一个是只应用,不删除该贮藏;另一个是应用并删除该贮藏:
最后,我们介绍一下.gitignore 文件。有一些文件我们并不想被 git 跟踪,比如 IDE 产生的临时文件、日志文件,涉及到密码的某些文件(比如.env) 等等。这些文件我们可以在.gitignore 文件中进行配置,git 就会忽略这些文件。
.gitignore 文件的每一行都是一个符合 glob patternglob 的字符串匹配模式。被该模式匹配到的文件(或者文件夹),将不会被 git 跟踪。我们可以手动编辑这个文件,但一般地,我们应该使用相关的扩展来协助管理此文件。
2.4. 与他人同步变更:git push 和 git pull¶
前面的操作只是把变更记录在本地的 git 系统中。为了使得这些变更能为他人所见,我们得把这些变更推送到远程仓库中。
1 | |
-u 参数是为了将本地的 main 分支与远程的 main 分支关联起来,在以后的推送或者拉取分支时,就可以简化命令:
1 2 3 4 5 | |
注意,本地仓库与服务器关联的命令(即git remote add)只需要执行一次;而每次创建了新的分支后,都要在第一次往该分支推送变更时,执行git push -u ...这个命令,以便在推送的同时,也完成本地分支与远程分支的绑定。一旦绑定完成,在随后的推送(或者拉取)动作中,就可以省略-u 参数。

2.5. git 标签¶
随着开发的进行,终有一天,我们会到达某个重要的节点,比如某个版本的完成。此时我们就会给仓库的状态打上标签,方便回溯。这就需要用到 git tag 的一系列命令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
这里我们稍作停顿,解释下标签究竟意味着什么。前面我们说过,创建标签是给仓库的某个状态打上标记的动作。在上面示例中的第 14 行和第 15 行,我们在没有任何新的提交的情况下,连续创建了两个不同的标签。考虑到我们的仓库是一个线性的提交历史,那么这两个标签究竟指向了什么呢?随后,第 23 行的命令输出显示了,这两个标签指向了同一个提交,即 57eb。这两个标签关联的都是 57eb 提交之后的仓库状态。这也说明,标签与提交本身不是一对一的映射,而是多对一的映射。
既然标签是指向提交的,您可能会想,我们是不是可以为过去的某个状态追加标签?您的猜测是正确的,我们确实可以这样做:
1 2 | |
Info
前面讲过,在 git 中,许多对象的标识符都是一个 hash 串。每一次提交的标识符 (commit id) 也是一样,它是基于 SHA-1 算法的一个 40 字节的 hash 串。
在刚刚的命令示例中,我们使用了提交 (commit) 的 hash 串的前 4 个字节代替整个 hash 串。在 git 中,我们可以只使用提交的 hash 串的前若干个字节来代替整个 hash 串,只要它是唯一的、并且至少包括 4 个字节。
也许您会感到好奇,如果一个项目足够大,commit id 发生 hash 碰撞的几率就会变大,那么最终我们可能要使用多少个字节,才能唯一地确定一个 hash 串呢?Linux 的内核是一个相当大的 Git 项目,截止 2019 年 2 月止,共记录了超过 875,000 个提交,通过计算得知,最少需要 12 个字符才能保证唯一性。
我们前面讲过,几乎所有的 git 操作都是多阶段的,创建 tag 也是一样。当我们执行git tag -a命令时,我们只在本地仓库创建了这个标签,我们仍然需要把它同步到远程服务器上:
1 2 3 4 5 | |
也有可能我们需要删除标签,这也是一个两阶段的操作
1 2 3 4 5 | |
标签创建以后,我们使用到该标签的常见操作是检出这个标签指向的文件版本,比如在 CI 服务器上检出这个版本制作构建(build)。此时我们可以使用 git checkout 命令:
1 | |
如果我们签出某个标签的目的是为了进行修改,注意这种情况下,我们应该为这个检出创建一个新的分支。然后我们就可以在这个工作区里进行修改,再推送到服务器上。如果我们不创建新的分支,而直接对签出到工作区的代码进行修改,会导致仓库处于“分离头指针 (detached HEAD)”的状态。这种状态下,我们可以进行修改,但无法提交,也就是说,这些修改最终会丢失。
至此,我们基本上接触到了 git 中全部基础的操作。我们学会了如何创建仓库,跟踪变更,提交变更,与远程服务器同步,并且创建标签以记录开发中的重要时刻。当然还有一些查错性质的操作我们没有介绍,比如查看日志 (git log),读者可以自行了解。另外,在掌握 git 的工作原理之后,我们更倾向于通过图形界面来管理 git 仓库,因此象查看变更历史这样的操作,也应该通过图形界面来查看。
Info
回想起多年前的那个夜晚,如果我们当时已经使用了了版本管理加 CI/CD,那将是无数个美好的夜晚之一。实际上,直到夜里两点之前,一切都非常美好,项目组准备用来庆功的陈年茅台已经开启,那淡金色的液体和馥郁的酱香令人难忘。
然而,git 中真正高级的技巧都与分支相关,这也将是我们接下来要讲述的内容。
3. 分支管理¶
几乎所有的版本控制系统都以某种形式支持分支。使用分支意味着可以进行多个功能(或者热修复)的并行开发,换言之,可以实现多人同时开发,或者一个人同时跟进几个功能的开发,而代码最终还能比较容易地合并起来。
有人把 Git 的分支模型称为它的“必杀技特性”。因为与其它版本管理工具相比,Git 处理分支的方式可谓是难以置信的轻量,创建新分支这一操作几乎能在瞬间完成,并且在不同分支之间的切换操作也是一样便捷。与许多其它版本控制系统不同,Git 鼓励在工作流程中频繁地使用分支与合并,哪怕一天之内进行许多次。
Git 的分支管理能做到如此优秀,根源还在于它的底层设计。我们前面讲过,git 与其它软件不同,git 保存的不是文件的变化或者差异,而是一系列不同时刻的文件快照。它的特征是以储存空间来换取时间(性能)的。
直到现在,我们都没有赋予分支一个清晰完整的定义。我们可以这样来理解分支:假设我们正在开发一个博客网站。开发小组有 4 个人,功能有持久化与缓存模块、文档对象抽象模块、主题与展示模块、评论管理模块等功能。如果每个人负责一个功能,那么效率最高的开发模式应该是每个人都在自己的分支上独立开发,完成自己模块的单元测试,再合并到一个共同的分支(比如称作 develop) 上进行集成测试。当集成测试完成时,再合并到 main 分支上完成版本发布,接下来进入下一个功能迭代。
此外,我们还会遇到这样的情况:网站的 1.0 版本发布后,已经开始了新的功能开发,但有紧急的 bug 需要修复,这时,我们需要切换到线上的分支(即 main 上面的某一个标签),创建一个 hotfix 分支,修复 bug,测试和发布,最后合并到 main 分支,以及集成分支 (develop) 上。
上述开发场景是比较典型的一个场景。2010 年,Vincent Driessen 将其抽象成了一个工作流模型,在此后的 10 多年中,该模型得到了广泛的认可。bitbucket,由著名的 Atlassian 公司出品的支持 git 版本库托管服务,也在其官方文档中推荐了这个模型。Vincent 还基于这个模型,开发了 git 的扩展 gitflow,以帮助人们更好地运用这个模型。到目前为止,这个项目在 Github 上获得了 26.1k 的 star。
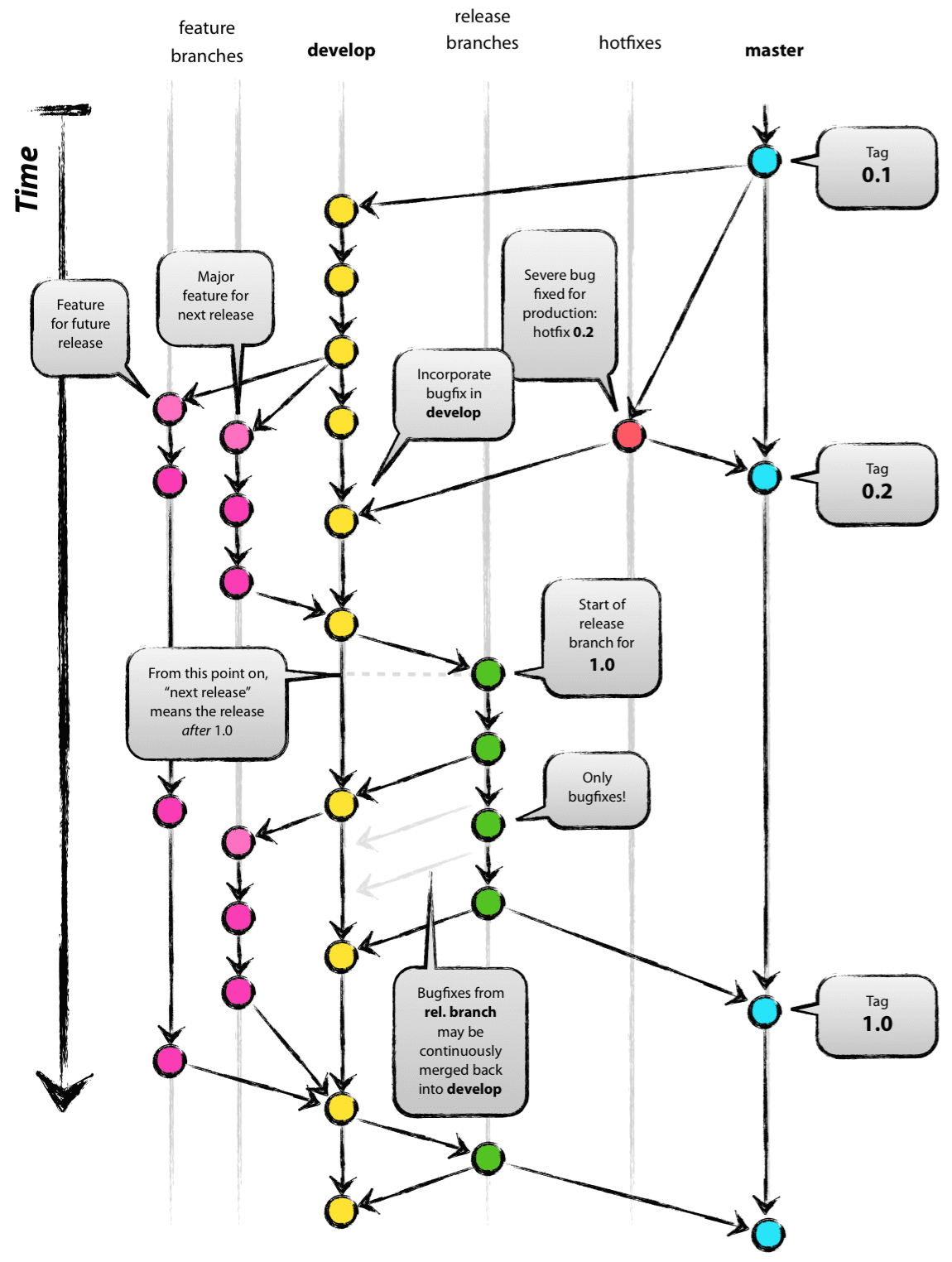
在这个模型中,服务器上始终存在两个分支,即 main 分支(原图中的 master)和 develop 分支。main 分支的 head 指针应该指向已发布的产品构建时的状态,也就是我们应该随时可以使用 main 分支构建出一份可用的产品出来。develop 分支可以认为是一种集成分支,它的 head 指针应该反映出下一个发布的最新开发状态。这也是我们用来制作夜间构建(nightly build)的分支。
当 develop 分支上的代码达到某个稳定的状态,已经准备好发布时,所有的这些变更应该合并到 main 分支上,并且打上带版本号的标签。从定义上来讲,每次有变更合并到 main 分支时,都应该产生一个新的发布版本。因此,往 main 分支上做合并应该非常严格,需要使用钩子来保证 CI 过程自动构建软件和测试,并完成部署(或者向 pypi 发布)。
如果开发者是一个团队,显然从 develop 分支往 main 分支上的合并,应该是 develop lead 的工作。
除了 main 和 develop 之外,我们还会有一系列的辅助分支,它们只会临时存在,并且最终会被移除掉。这些分支是: 1. 功能分支(Feature branches) 2. 发布分支 (Release branches) 3. 热修复分支 (Hotfix branches)
这些分支都有自己的特定目标,因此,它们的来源和最终合并的去向也遵循严格的规则。
3.1. 功能分支 (Feature branch)¶
功能分支是从 develop 分支上创建出来的,用来开发某个新功能。当功能开发完成时,需要合并回 develop 分支。我们可以使用{{feature_name}}/{{developer}}来命令分支。这里 feature_name 是功能的名字,developer 是团队中负责这个功能的开发者。当然,如果功能只有一个人负责开发,也可以省略 developer 这一部分。
我们应该这样创建一个功能分支:
1 | |
在开发的过程中,我们应该及时把变更提交并推送到远程服务器上,以避免代码丢失,也方便其他人进行 code review。当功能开发完成时,我们应该及时把变更从功能分支合并回 develop 分支,并删除功能分支。以下是操作命令示例:
1 2 3 4 5 6 7 8 9 10 11 | |
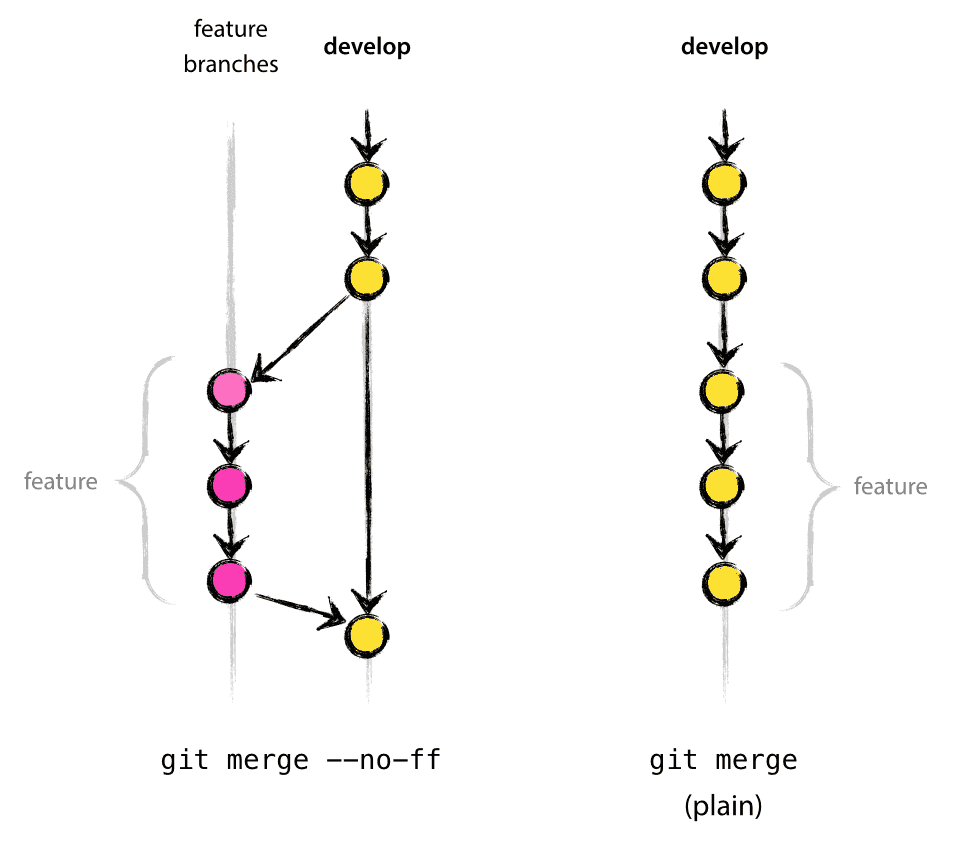
上图中右边的部分显示了一个普通的合并(即没有指定--no-ff 选项),在这里,看不出来哪些提交构成了一个功能(除非检查日志),更不用说 feature 分支的存在了。另外,在右边这种情况下,回滚整个功能也会是令人头疼的事。
3.2. 发布分支(Release branch)¶
发布分支 (release branch)用来准备一个新的发布,用以完成正式发布前的每一个细节。这个分支也允许小的补丁和一些 meta-data 的变更(比如版本号,构建日期等)。一旦 release 分支被创建,develop 分支就可以继续开发下一个版本的功能了。当发布完成,需要合并回 develop 分支和 main 分支。分支名一般使用 release-*。
从 develop 分支迁移到 release 分支应该发生在所有的功能都合并到 develop 之后,而任何不属于此次发布的功能,则绝对不应该在此前进入到 develop 分支。
只有在 release 分支创建时,我们才应该确定版本号。创建 release 分支的命令是(假设之前的版本是 1.1.5,最新的版本定为 1.2):
1 2 3 4 5 6 7 | |
当 release 分支最终稳定下来,可以发布时,我们应该把 release 分支合并到 main 分支,并打上一个 tag。这个 tag 的名字应该和版本号一致(一般以 V 开头)。最后,将 release 分支合并到 develop 分支上,即把所有的变更带入到下一个版本中。
合并 release 分支到 main 分支的命令是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
1 2 | |
3.3. 热修复分支¶
热修复分支 (hotfix branch) 从 main 分支上分出来,用来修复线上的 bug。当修复完成,需要合并回 main 分支和 develop 分支。分支名一般使用 hotfix-*。
热修复分支的主要作用是使得在 develop 分支上的开发者不受影响,而其它人则可以快速修复线上的 bug。具体的操作命令与前面的示例大同小异,这里不再赘述。不过需要提醒的是,我们一样要给 hotfix 分配版本号并打上标签。
如果在进行热修复时,已经存在 release 分支,此时 hotfix 应该合并回 develop 分支,还是 release 分支?答案是 release 分支。如果 hotfix 被合并到 develop 分支,那么这个 hotfix 将只能随下一个版本发布而发布,这是不合理的。因此,hotfix 应该合并到 release 分支,最终,它将随 release 分支再合并到 develop 分支中,从而保证进入后续版本。
下图演示了 hotfix 中的变更在各分支之间的流动:
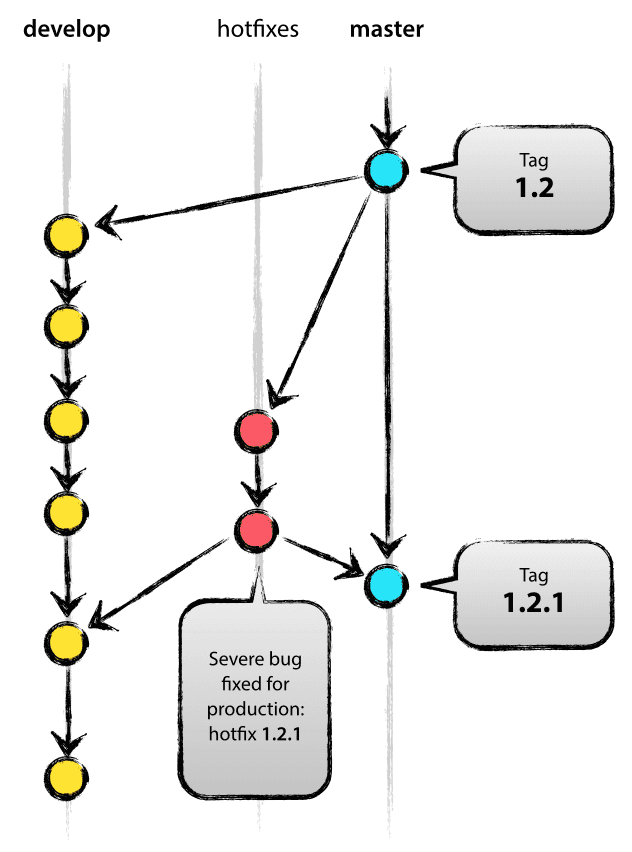
在介绍本节内容时,我们较多地参考了 Vincent Driessen 的博客文章 《A successful Git branching model》。这篇文章是 Git 分支模型的经典之作,建议读者做延伸阅读。Vincent Driessen 开发的 gitflow 工具是 git 的一个扩展,用来实现上述工作流,这里也推荐安装使用。
4. Git 中的高级操作¶
4.1. 分支合并和三路归并¶
在分支管理那一节中,我们已经提及了 merge(分支合并)这个概念,但我们没有具体讲如何操作。这一节,我们将以 hotfix 的发布为例,介绍分支合并与三路归并 (3-way merge) 操作。
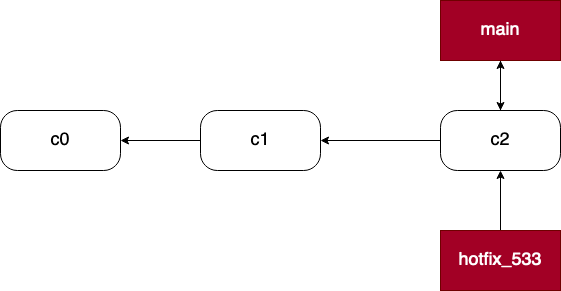
假设我们的产品已经发布了 1.1,现在团队正在开发 1.2 版本。在开发过程中,线上版本发现了一个严重的 bug(在 tracker 系统中编号为 533),需要立即修复。按照 gitflow 的模型,我们应该从 main 分支上切出一个 hotfix_533 分支,修复 bug 后,再合并回 main 分支和 develop 分支。
下图展示了 hotfix_533 分支创建时,相关分支的状态图:
当我们修复完这个 bug 后,产生了一个新的提交,记为 c3, 它的父结点是 c2。这个提交发生在 hotfix_533 分支上,所以我们还必须将其 merge 回 main 分支。假设我们在修复 issue 533 时,线上还发现一个新的 bug,记为 issue 534。而这个 hotfix 完成得更早,产生了记为 c4 的提交,已经合并到了 main 分支。此时,相关分支的状态图如图 8- 12 所示:
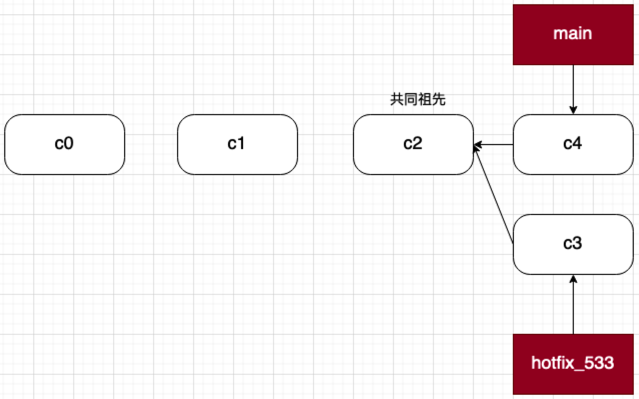
如果提交 c4 和 c3 修改互不冲突(比如修改的文件不同,或者即使是同一文件,但修改的行不同),这样 git 一般可以直接合并,如果相互冲突,则我们还要手动解决冲突。
我们先看没有冲突的情况。在前面的例子中,我们都是以 git 的原生命令,以命令行的方式来进行演示。但从现在起,我们可能更多地使用图形化界面来举例,并提及发生在背后的 git 命令。
首先,我们将 c4 从 hotfix_534 分支上 merge 回 main 分支。我们要先切换到 main 分支,再在下面的界面中,将鼠标移动到 hotfix_534 那个条目上,再右键唤出上下文菜单,如下图所示:
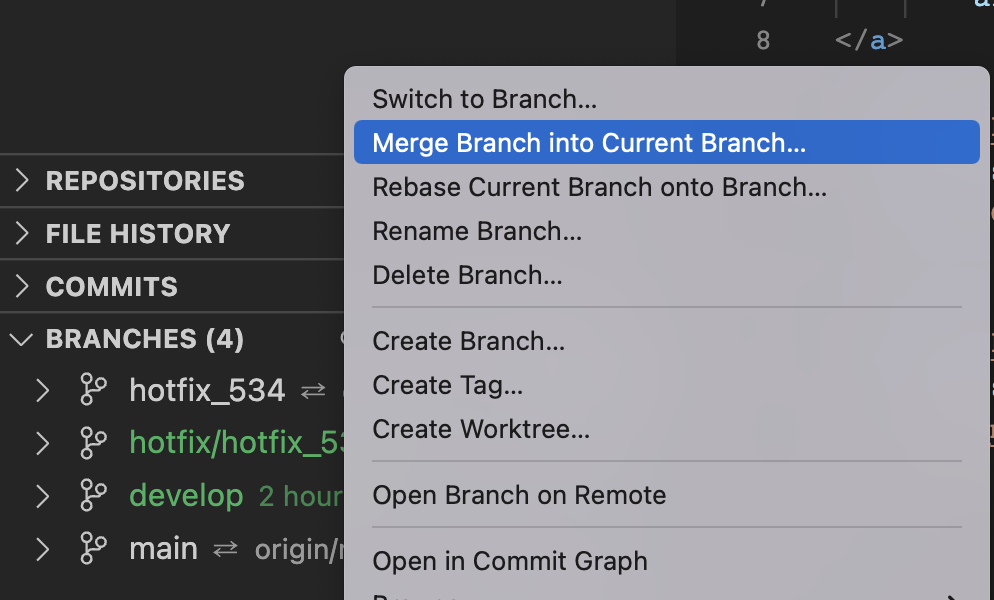
点击“Merge into current branch”,在接下来的对话框中,选择"Merge"(对应的命令是 git merge), 如下图所示:
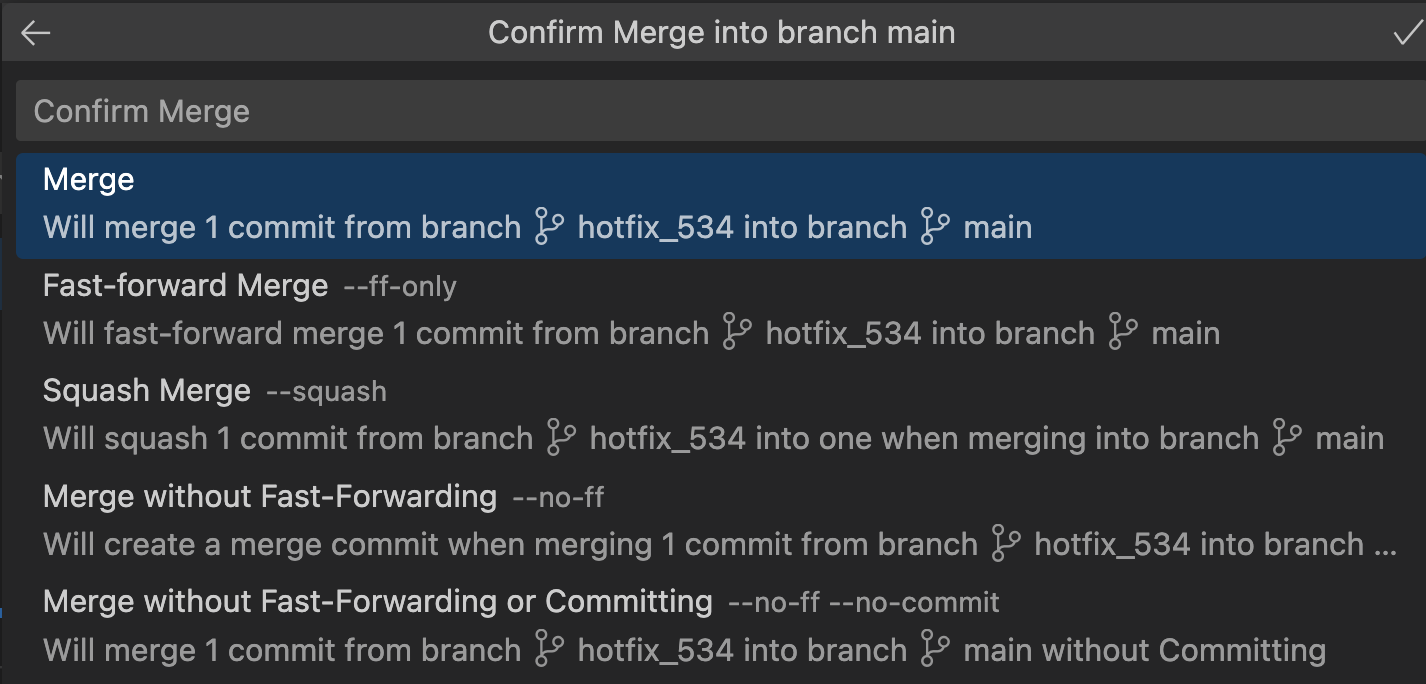
前面的例子中,我们一般使用 git merge --no-ff,在这个例子中,我们却使用了 git merge。这是因为,hotfix 属于短生命期的分支。如果我们工作在 develop 分支上,我们应该使用 git merge --no-ff,这样可以保留 develop 分支的历史记录。如果你希望针对不同的分支,对 merge 动作定制不同的默认行为,可以通过修改 gitconfig 文件来实现,请感兴趣的读者自行研究。
如果 c4 与 c3 相互冲突呢?这种情况被称为三路归并,我们需要手动解决冲突。从 vscode 1.69 起,vscode 提供了三路归并编辑器,大大方便了合并,也终于补齐了它与 pycharm 之间最大的一块短板。
我们需要在 vscode 的设置中,打开相应的开关:

此时再执行合并,我们会看到以下界面:
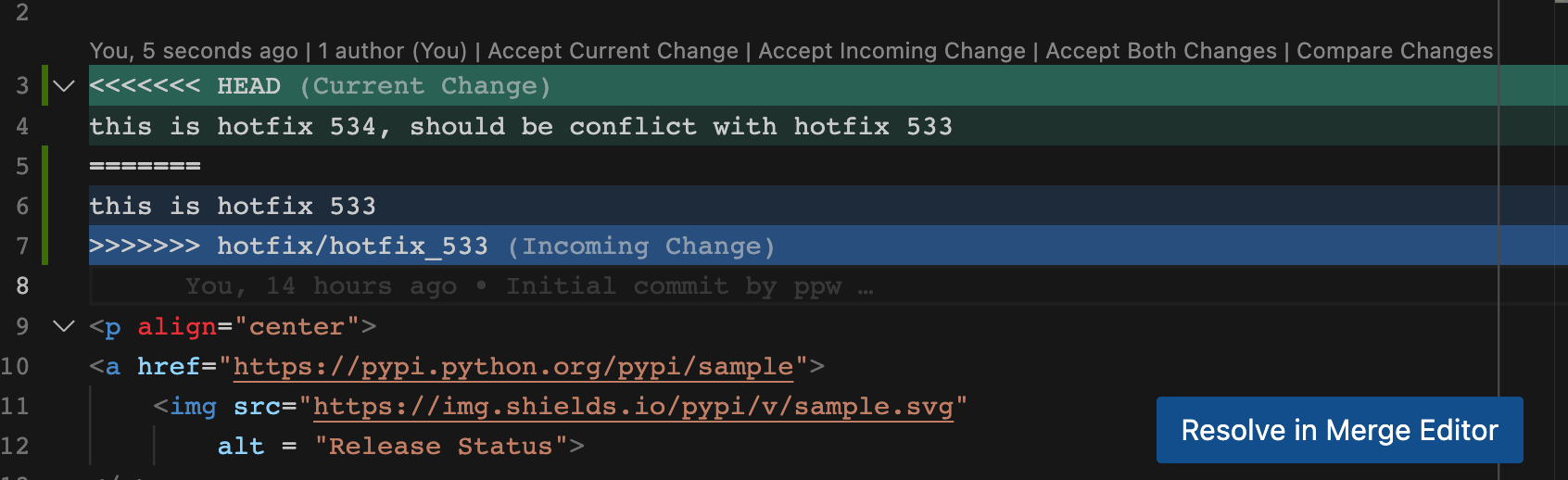
我们点击"Resolve in Merge Editor"按钮:
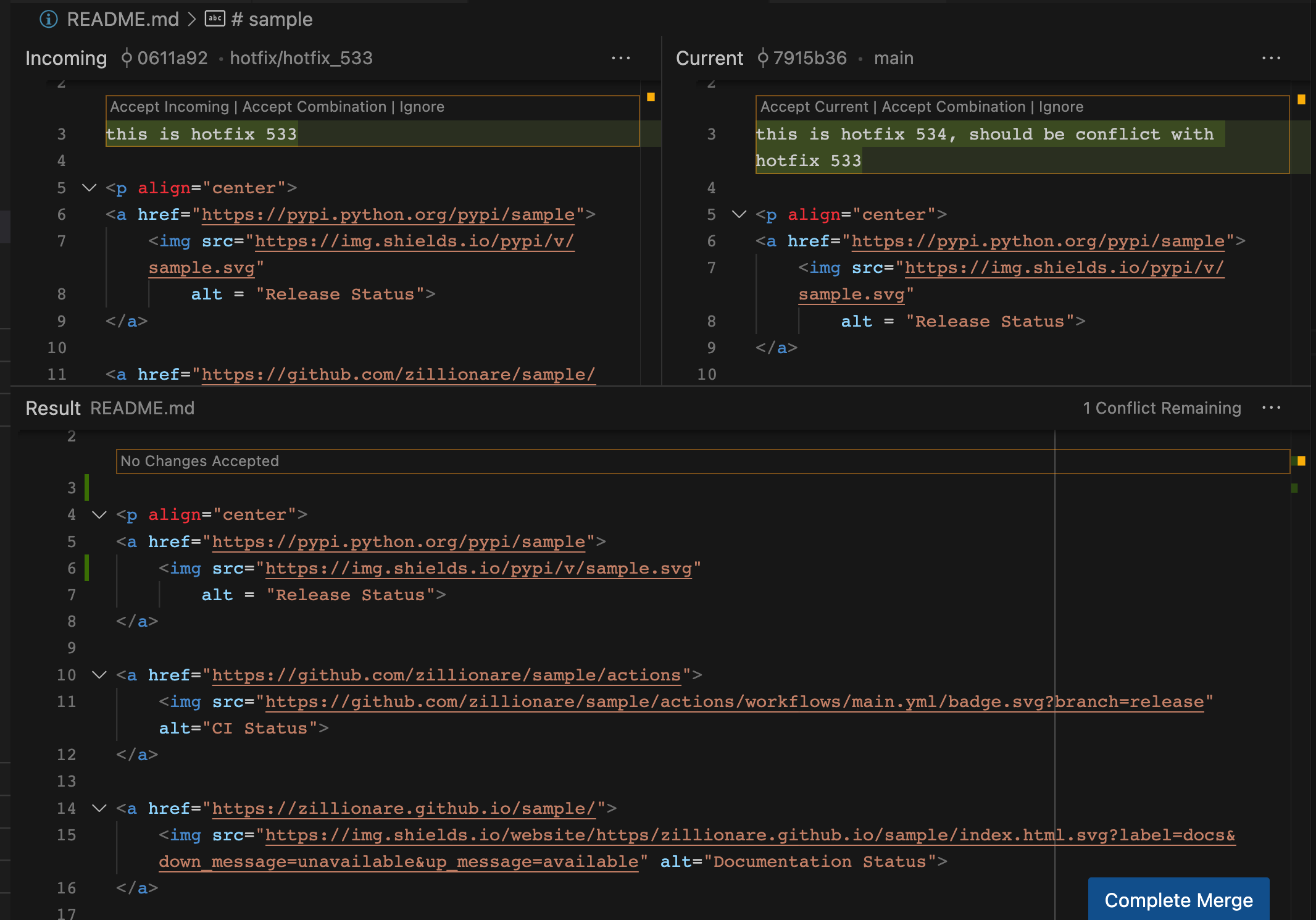
左边的是 hotfix_533 分支,右边的则是 main 分支,两个改动相互冲突。如果我们接受 hotfix_533,则可以点击顶部的"Accept Incoming"按钮,如果我们接受 main 分支,则可以点击底部的"Accept Current"按钮。如果我们希望保留两个分支的改动,则可以点击中间的"Accept Combination"按钮,将两个修改同时保留。我们也可以全部拒绝两个修改,这样只需要编辑下面的 result 窗口中对应行(图中的第 3 行)就行了。
当一个文件中的所有冲突都被解决之后,点击“Complete Merge”按钮关闭编辑器,完成合并。
4.2. rebase¶
变基是另一种合并分支的方式。变基的目的是将一个分支的改动,移动到另一个分支上。假设我们有以下状态:
如果我们使用 git merge 的方法来进行合并,我们将得到下图:
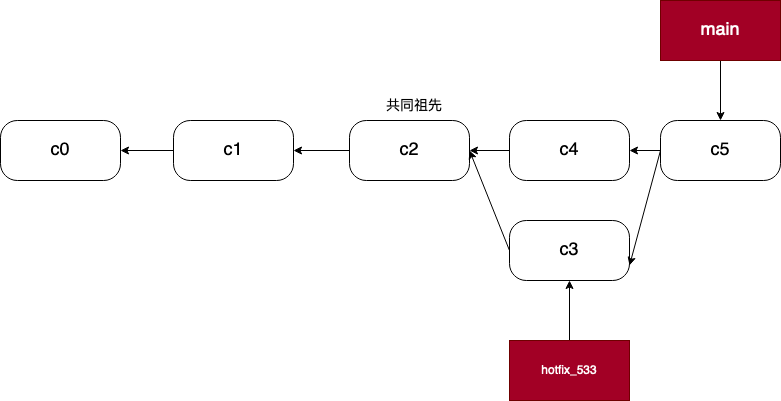
我们也可以对 hotfix_533 进行 rebase 操作,使得 c3 的父结点从 c2 变为 c4:
1 2 3 4 | |
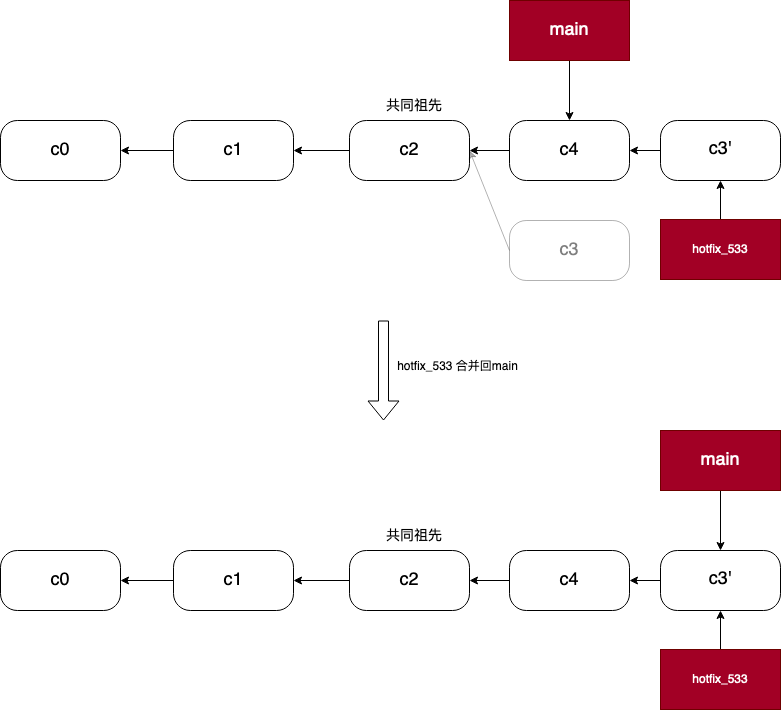
与不使用 rebase 相比,进行 rebase 之后,分支历史将不会出现分叉,这样可以使得分支历史更加清晰。
至此,我们已经介绍了变基和合并都用于代码合并,你一定会想问,到底哪种方式更好,两种方法,分别在何时使用?实际上,无论使用哪种方法,代码的最终状态都必然是一致的,不同的只是提交历史。
有一种观点认为,仓库的提交历史即是记录实际发生过什么。它是针对历史的文档,本身就有价值,不能乱改。 从这个角度看来,改变提交历史是一种亵渎,你使用谎言掩盖了实际发生过的事情。如果由合并产生的提交历史是一团糟怎么办?既然事实就是如此,那么这些痕迹就应该被保留下来,让后人能够查阅。
另一种观点则正好相反,他们认为提交历史是项目过程中发生的事。没人会出版一本书的第一版草稿,软件维护手册也是需要反复修订才能方便使用。持这一观点的人会使用 rebase 来编写故事,怎么方便后来的读者就怎么写。
现在,让我们回到之前的问题上来,到底合并还是变基好?这并没有一个简单的答案。 Git 是一个非常强大的工具,它允许你对提交历史做许多事情,但每个团队、每个项目对此的需求并不相同。 既然你已经分别学习了两者的用法,相信你能够根据实际情况作出明智的选择。
不过,我们要强调的是,rebase 是一种高级操作,在一些复杂的提交组合下(比如多人协作开发时,有人对已推送的提交进行了回滚),使用 rebase 可能会导致意想不到的结果。因此,在你深入理解 rebase 的工作原理之前,也可以只使用 merge。
4.3. 分支比较:git diff¶
在进行代码合并前,我们常常会在不同的分支间进行比较,以便了解两个分支的差异。它也帮助我们在合并之前就发现有哪些合并冲突。
Git 提供了 git diff 命令来比较两个分支的差异,不仅如此,它还可以比较两个提交之间的差异。我们先简单介绍下 git diff 命令行下的一些用法,然后就跳转到图形化界面。毕竟,图形化界面可以显示出更多的信息。
在调用 Git diff 时,显然我们需要给它提供待比较的分支名。这里又有所谓的两点语法和三点语法。前者是两个分支直接比较;后者则会引入共同祖先一起进行比较。
1 2 3 4 5 6 7 8 9 10 11 12 | |
现在,我们来看看在 git lens 扩展中,如何比较两个分支。首先,我们在下面的菜单(图 8- 21)中,选择要比较的两个分支:
然后我们在"Search & Compare"面板下,找到对比结果:
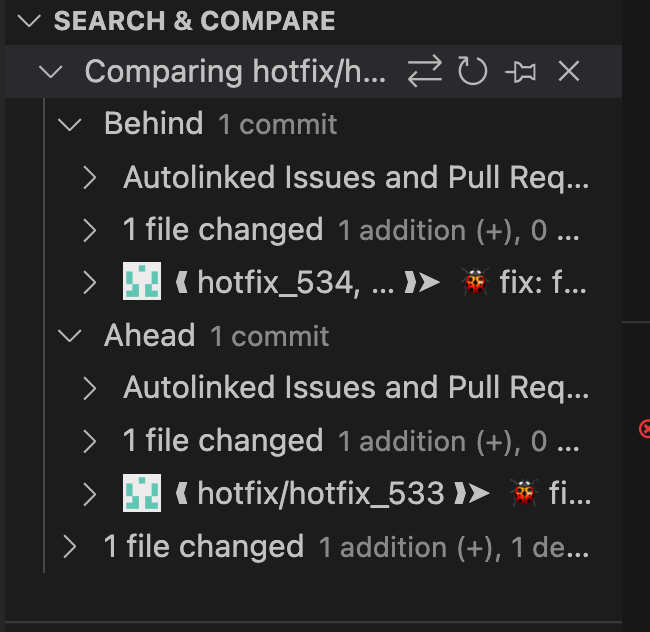
注意到在"Comparing hotfix/..."字符串后面,有一个交换图标。它用来交换 git diff 两点语法中的两个分支的顺序。要查看文件内容的变更,可以在"1 file changed"的下拉菜单中,找到变化的文件名,然后点击它就可以浏览变更的具体情况了。
4.4. reset 与 checkout¶
前面我们已经接触到了 checkout 命令。这里再介绍一个类似的命令,即 reset。
要理解 reset 命令,我们需要先回顾下 git 的三棵树模型,即工作区、暂存区 (index) 和 HEAD。reset 命令的作用是将当前分支指向某个提交,同时重置暂存区和工作区,使它们与指定的提交一致。
假设我们有如下提交历史:
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 3 4 5 6 7 8 9 10 | |
现在我们将 README.md 再提交一次,然后再执行 reset 命令:
1 | |
如果我们使用--hard 参数来执行 reset,那么,我们还将取消文件的变更本身:
1 | |
如果我们从图形界面上执行 reset 操作,大概分这么几步。首先,我们找到 COMMITS 面板,然后找到要重置的提交,点击它,选择"undo commit"操作,这相当于执行了一个”reset --soft HEAD~"操作。
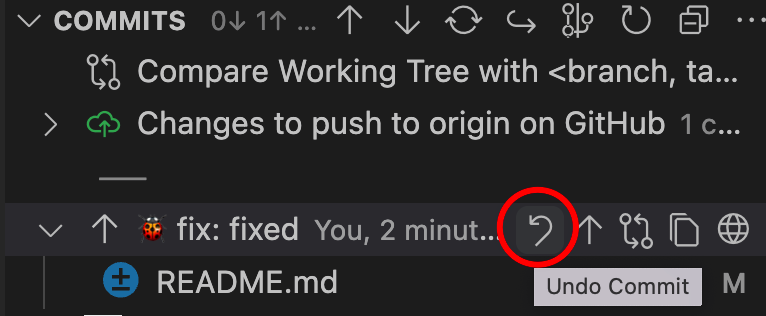
如果我们还要取消"stage"操作(即 undo add),则可以在“SOURCE CONTROLE”面板中,找到 staged changes,再点击“unstage all changes"按钮。同样的操作还可以运用在"Changes"类别下面的文件上,这里就不再赘述。
4.5. gutter change¶
在我们前面介绍暂存操作时,都是以整个文件为单位进行暂存。但是,有时候,我们可能应该把某一个文件分为几个不同的批次来添加。这个命令在 git 中称为交互式暂存 (interactive staging)。通过命令行执行比较繁琐,这里我们介绍 git lens 中的 gutter change 功能,如下图所示:
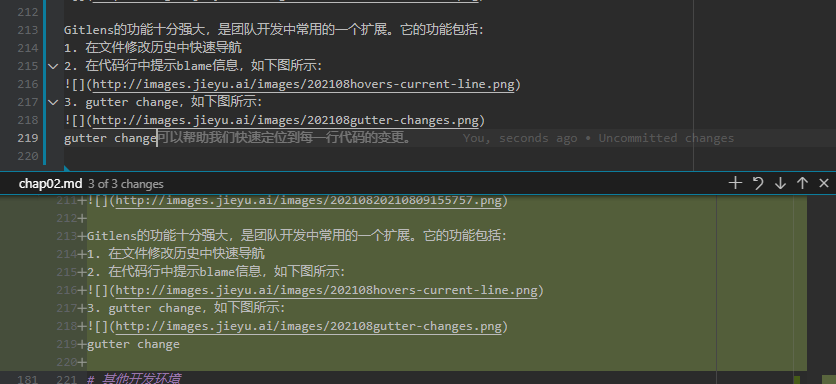
gutter change 是指如上图所示,在编辑区行号指示右侧,通过一个线条来指示当前区域存在变更,当你点击这个线条时,会弹出一个窗口,显示当前区域的变更历史,并且允许你仅对这几行变更进行回滚或者提交。
5. 谁引入了错误:如何追踪代码变化(案例)¶
假设一组人共同开发一个功能,其中有一个人提交了一个错误的代码,这个错误的代码被合并到了主分支,导致了线上的故障。一个紧急的修复版本发布后,问题修复了。过了一段时间,团队决定开一个事后分析的会议,希望知道错误是如何引入的,今后如何举一反三,避免类似错误。
通常,如果错误代码还留在当前的代码中,显然我们只要通过 git blame 就可以知道是谁提交的。如果安装了 git lens,只需要将鼠标移动到该行代码末尾,git lens 就会显示该行代码的提交历史,如下图所示:
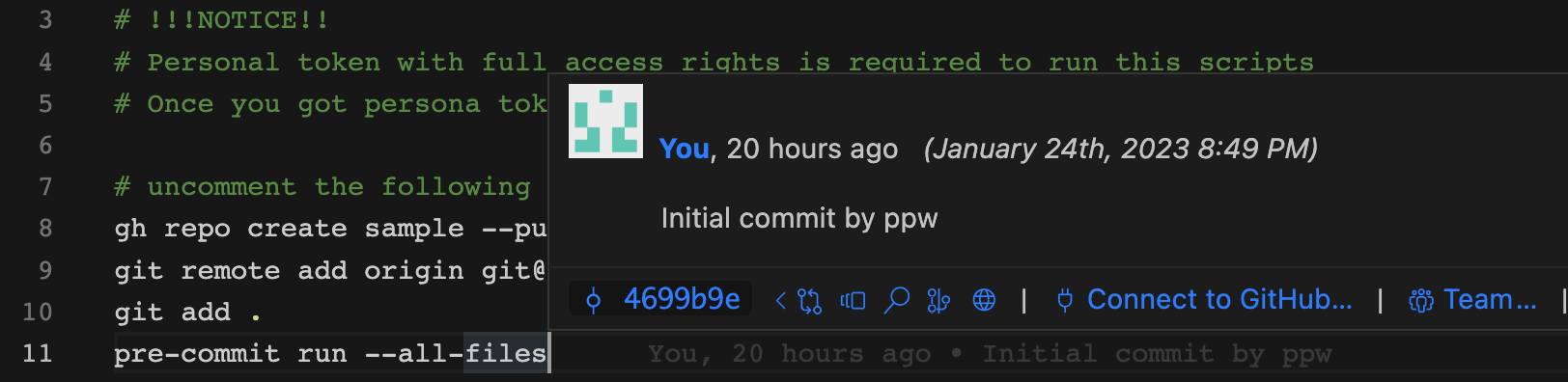
但是,由于我们已经修复了该错误代码,并且也过去了一段时间,所以该段代码已经从代码中删除了。现在,惟一的线索,就是只知道可能是一个错误的字符串引起了这个 bug。那么,如何通过这个字符串来搜索呢?
答案是 git log 命令+git blame 命令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
1 2 | |
6. Github 和 github cli¶
GitHub 是一个在线软件源代码托管服务平台,使用 Git 作为版本控制软件,由开发者 Chris Wanstrath、P. J. Hyett 和汤姆·普雷斯顿·沃纳使用 Ruby on Rails 编写而成。Github 开始于 2007 年 10 月 1 日, 2008 年 4 月正式上线。在 2018 年,GitHub 被微软公司收购。
Github 除了允许个人和组织进行版本管理外,它还提供了某些社交功能,包括允许追踪 (follow) 其他用户、组织、软件库的动态,对软件代码的改动和 bug 提出评论等。GitHub 也提供了图表功能,用于显示开发者们怎样在代码库上工作以及软件的开发活跃程度。
Info
据统计,github 用户中,男性群体高达 95%以上,因此 Github 也常被网友戏称为 Gayhub,全球最大同性交友网站。
截至 2022 年 6 月,GitHub 已经有超过 5700 万注册用户和 1.9 亿代码库(包括至少 2800 万开源代码库),事实上已经成为了世界上最大的代码托管网站和开源社区。它托管的巨大源代码库,也成为 copilot 的训练数据集。
除了作为 Git 的托管服务平台外,github 还提供了 Github pages 网页托管服务(可存放静态网页,包括博客、项目文档甚至整本书);codespace 在线开发环境和 Github actions CI 等服务。
Github 网页版的功能留给读者自己探索。这里主要讲解下 Github cli 的功能和用法。
除了网页之外,Github 还提供了一些 REST 风格的 API 供大家使用,现在可以使用的 API 版本称为 V3。通过这些 API,我们可以管理仓库、访问用户、构建和触发 CI、管理 issue 等。
这些 API,使得我们可以通过 curl 来完成上述功能。Github 还基于这些 API,开发了一个命令行工具,github cli,简称 gh。
6.1. 安装¶
在 mac 下安装 gh,可以使用 brew 安装:
1 | |
在 linux 和 bsd 下安装,如果是 Debian, Ubuntu Linux, Raspberry Pi OS 等基于 apt 的系统,可以使用 apt 安装:
1 2 3 4 5 6 | |
1 2 3 | |
如果是 windows,可以通过 winget, scoop, Chocolatey 等包管理工具安装,也可以直接下载 安装包 安装。
最后,如果在所有的操作系统上,如果您已经安装了 conda,则也可以通过 conda 来安装:
1 | |
6.2. Github cli 的主要命令¶
Github cli 的主要命令有:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | |
6.3. Github cli 应用举例¶
Github cli 可以方便我们对账户和仓库执行一些自动化的操作。在 ppw 创建的项目中,有一个名为 repo.sh 的脚本,这里面就使用了 Github cli。
当 ppw 生成了框架代码之后,我们需要把它提交到 Github 上去。由于此时 Github 上还没有这个仓库,我们必须等用户手动创建,因此这个提交也没法自动化。当我们使用了 Github cli 之后,这个问题就解决了:
1 2 3 4 5 6 7 | |
另外,通过 Github 的 web 界面来设置仓库的一些机密信息比较繁琐,耗时较长。假设你管理了 10 个以上的仓库,还要定期更换这些机密信息的话就更是如此。我们可以通过 gh secret 命令来解决这个问题。下面的代码摘录自 repo.sh:
1 2 3 4 5 6 7 8 9 | |
在 ppw 生成的项目中,当 CI 运行时,需要有 pypi 和 test.pypi 的 API key, 发布文档时需要 Github 的 API key, 以及 CI 完成时,需要发送邮件通知,这需要配置相关服务器信息及发件人、收件人信息等诸多敏感信息。
通过上述脚本,我们把当前宿主机上的环境变量导入到了仓库的机密信息中,这样在 Github actions 中就可以直接使用了。这个过程中,我们既保证了方便,又保证了机密信息的安全性。