给Pandas找个搭子,用SQL玩转Dataframe!
对有一定SQL基础的人来说,pandas中的查询会有点繁琐。
在这篇文章,我们将给Pandas找个搭子,在用SQL方便的地方,我们用SQL;在用原生查询方便的地方,我们就用原生查询。
这个搭子会是谁呢?
Info
这篇文章强调的是,有SQL基础的人,使用SQL来完成某些dataframe的查询会更简洁直观。但并不是所有的时候,我们都可以用SQL来代替dataframe的操作。两种方式各有长处。pandas中我们对数据的操作是分步的,渐进式的,可以一步步地查看中间处理结果,这是它最大的优点。
dataframe方法 vs SQL¶
dataframe是一个数据表格。pandas提供了很多方法来实现对dataframe的查询,这些查询往往可以与sql查询对应起来,比如:
- 选择表中的几列。对应的SQL语句是:
在pandas中,这个语法更简洁一些:
1SELECT total_bill, tip, smoker time from tips;1tips[["total_bill", "tip", "smoker", "time"]] - 按条件查询。在条件较多,或者需要模糊匹配时,就不如sql简洁了
sql语法有自然语言之感。在pandas中,需要这样查询:
1select * from tips where time like 'Dinner%' and tip > 5;对字符串的操作语法或许更强大,但没sql直观。多个条件的逻辑运算符也不如 and这样易懂。对空值的查询,在SQL中是1tips[(tips["time"].str.find("Dinner") == 0) & (tips["tip"] > 5)]在pandas中,需要使用isna()或者notna()。1select * from frame where col2 is NULL;
- 聚合运算也是数据处理中的常态。
在pandas中,需要这样查询:
1select smoker, day, count(*), avg(tip) from tips group by smoker, day;尽管语法不太直观,但书写上倒也简洁。1tips.groupby("day").agg({"tip": "mean", "day": "size"}) - 连接表。SQL有强大的join和union语法。在pandas中,提供了join, merge和concat三个函数来实现相关功能。其中join默认是按列进行左连接,merge则是按列内连接,concat则是按行进行外连接。设计了多个API来做类似的事,这是pandas给人增加学习和记忆难度的地方。join与merge的区别是,join可以一次处理多个表,但只支持按index进行操作。merge一次只能处理两个表,但可以按任意列进行操作。concat默认是按行进行操作,只按index进行内连接和全连接(默认),可一次操作多个dataframe。
此外,我们对数据还有排序、限制返回数量和分页的需求。这些操作在pandas中都有对应的函数,但对已经熟悉sql的人来讲,pandas的API很难与SQL一一对应上。
现在,我们就来看看,如何把dataframe当成一个数据库表,使用sql进行查询。如果这一功能得到实现,那么许多查询就可以得到相应的简化。
Tip
除此之外,我们最终给出的方案,还将大大增强查询性能,并且能处理大于内存的数据集!
内置的query方法¶
令人吃惊的是,pandas已经内置了一个query方法,可以让我们就像执行sql一样进行pandas的查询。
这个函数的签名是:
1 2 3 4 5 | |
通过这个query方法,我们可以简化查询。我们先来生成一个数据集:
1 2 3 4 5 | |
这里我们利用了testing包中的makeMixedDataFrame方法来生成测试用的dataframe。makeMixedDataFrame会生成一个包含各种数据类型的dataframe,除了None。如果要生成带缺失值的测试用dataframe,可以用makeMissingDataframe。
我们得到的dataframe类似于下图:
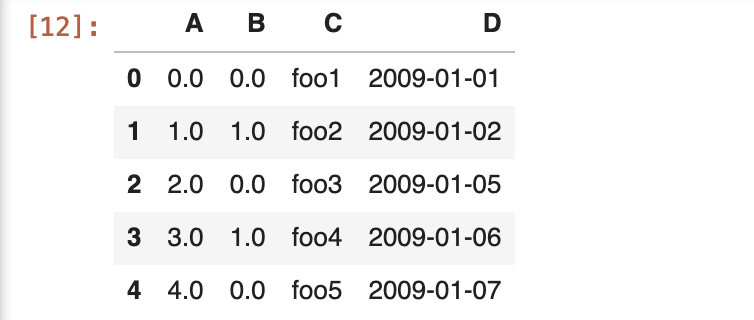
现在,我们来执行一个查询:
1 | |
这将返回原数据集中的第4条记录。
要注意的是,query表达式只是看起来象sql,但它并不是sql语法。它的第一个参数,即expr参数,是一个Python表达式,而非sql语句。在上面的示例数据中,如果我们要查找C列包含'foo'的数据,我们不能使用sql的like关键字,而是要使用以下方法:
1 | |
这样实际上差不多退回到了dataframe中的查询操作,只不过这里允许我们使用AND作为逻辑运算符。我们使用query最主要的目的是为了获得更快的速度。如果环境中已经安装了numexpr这个库,那么query将默认使用numexpr来加速计算,在dataframe超过100万行时,会比DataFrame的各种filter方法要快不少。
pandasql¶
最先尝试为pandas提供sql查询功能的是pandasql。
1 | |
现在,我们就可以使用完整sql语法来进行查询了:
1 2 3 4 | |

分组统计、限制返回记录和更改字段名一气喝成,这个例子中,充分体现了使用sql的优越性。
但是使用pandasql有一个比较重要的问题,就是它已经很长一段时间没有更新过了。在我的书《Python能做大项目中》提到过SQLAlchemy的版本管理问题,在这里也出现了。当我们现在安装pandasql时,它会安装SQLAlchemy的2.0版本。这个版本会导致以下错误:
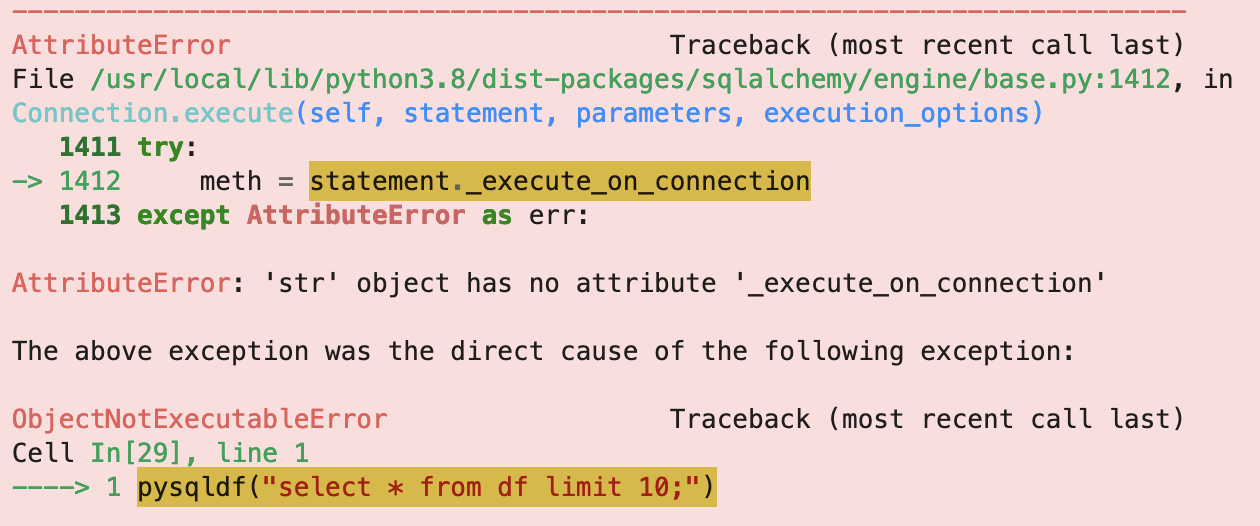
要解决这个问题,就需要退回到 SQLAlchemy 的1.4.46版本上来。但是,由于非常多的其它库(包括Pandas)会依赖SQLAlchemy的比较新的版本,所以这个方案实际上只会制造新的混乱。
我们继续寻找新的方案。这个方案,就是DuckDB.
DuckDB¶
Pandas是熊猫的复数,我们给它找的搭子叫Duck,似乎也是天生的一对,地造的一双。
Info
Pandas的名字来源于 Panel Data和Python Data Analysis,与Panda这种动物并无关联。但是DuckDB中的duck,则是实实在在来源于鸭子 -- 能走、能飞、能游泳,特别耐寒,生命力强 -- 据说,鸭子的歌声可以让人们起死回生。因此,它是完美的吉祥物。
DuckDB是一个进程内OLAP数据库管理系统,它主要使用SQL作为母语,但与Pandas,Polars,Vaex等DataFrame库有很紧密的集成。它基于c++开发,但提供了Python, R,甚至比较新的wasm接口。这里我们最关心的是以dataframe作为数据源来进行查询的功能。
Info
使用下面的命令来安装duckdb:
1 | |
我们先看一个最简单的例子:
1 2 3 4 5 6 7 8 | |
它甚至比pandasql还要简洁。我们不需要给duckdb绑定当前环境下的全局变量,duckdb能通自动查找到my_df!
关于duckdb,教学会非常简单。因为只要你熟悉sql,那么就已经几乎掌握了全部功能。这正是它的魔力之处。
不过,我们还可以举一个更强大的例子,在我们的量化场景下,常常会遇到。
As-of Join¶
作为开源量化框架的开发者,我曾深深为这个问题困扰:
如何得到复权后的分钟级别的行情数据?
分钟线行情数据常常只给出OHLC等字段,而不会给出复权因子字段。复权因子常常是在日线数据中给出的。因此,要得到复权处理后的分钟线数据,就必须将分钟线数据与日线数据的复权因子join起来。
困难在于,两者在时间上并不是对齐的,因此普通的join在这里无法使用。
duckdb实现了一个称为Asof Join的功能,来解决查找特定时间点的变化中的属性的值。Asof这个说法来自于下面的提问:
Give me the value of the adjust factor as of this time.
如果使用了duckdb,这个功能的实现会变得非常简单。为了演示真实的场景,我们使用量化24课环境下的数据源:
1 2 3 4 5 | |
1 2 3 4 5 6 7 8 9 10 | |
当然,通过zillionare-omicron获取到的分钟线,已经为我们做好复权处理了。为了演示,在这里我们通过duckdb的asof join功能来重新合成一次,并与zillionare的结果进行对照:
1 2 3 4 5 6 7 | |
输出结果是DataFrame格式,结果如下:
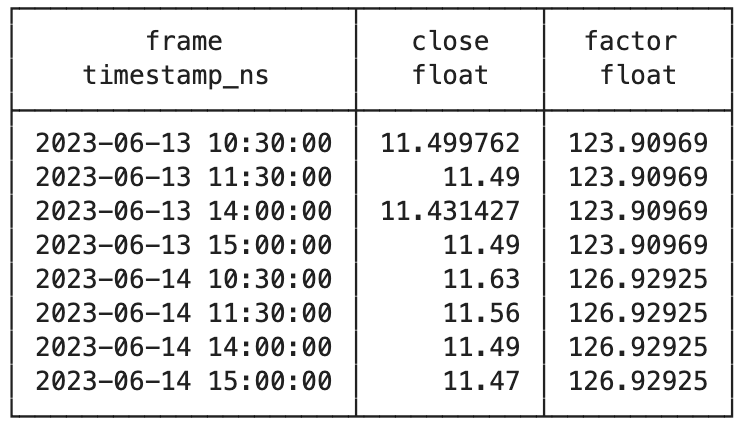
我们注意到2023年6月14日,发生了一次复权。接下来与zillionare-omicron获取的数据进行对比,我们要看复权发生的时间、复权因子以及收盘价是否一致:
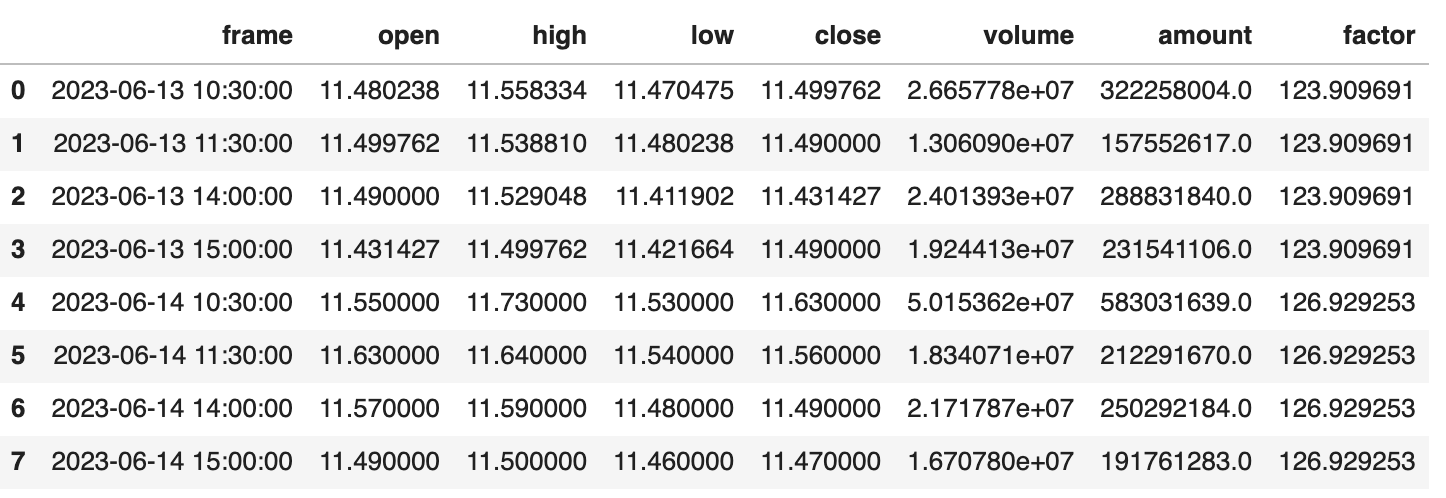
可以看到,两者结果是一致的。但是duckDB的实现,速度上要比zillionare快不少。
这篇文章主要是关于如何使用SQL来增强(或者说简化)pandas dataframe查询的。但是,duckDB的功能,却远不止于此。我们在之前的文章中介绍过,要存储海量数据,可以使用pyarrow + parquet。pyarrow承担了查询的任务。但是,如果你更喜欢使用基于SQL的查询,也可以使用duckdb。
从介绍pandas开始,到推荐使用duckdb + parquet,这算是一个欧.亨利式的结尾吗?