为什么量化人应该使用duckdb?
上一篇笔记介绍了通过duckdb,使用SQL进行DataFrame的操作。我们还特别介绍了它独有的 Asof Join 功能,由于量化人常常处理跨周期行情对齐,这一功能因此格外实用。但是duckdb的好手段,不止如此。
- 完全替代sqlite,但命令集甚至超过了Postgres
- 易用性极佳
- 性能怪兽
作为又一款来自人烟稀少的荷兰的软件,北境这一苦寒之地,再一次让人惊喜。科技的事儿,真是堆人没用。
sqlite非常轻量,基于内存或者文件作为存储,无须像其它数据库一样进行复杂的服务器安装和设置。它是市占率最高的数据库 -- 但未来可能会有所不同:仅就功能而言,duckdb不仅仅完全实现了sqlite的所有功能,它甚至可能比postgres的语法还要丰富。而在性能上,sqlite就更是难以望其项背 -- 实际上,在大数据集的join和group by操作上,H2O.ai的测试表明,在与clickhouse, porlars一众明星选手打排位赛,duckdb都能排在第一位!
替代sqlite¶
当我们使用sqlite时,特别是在进行单元测试时,我们可能使用内存数据库。duckdb也支持:
1 2 3 | |
如果将":memory:"换成文件名,就是连接到文件数据库了。这些与sqlite没有任何区别。
sqlite与duckdb都有rowid的概念。在duckdb中,rowid是一个伪列:
1 2 3 4 5 | |
如果某行被删除,该rowid会被回收,后面可能会被复用,因此,rowid不具有惟一性,不推荐作为行标识符。
在实现自增ID方面,sqlite可以通过autoincrement关键字来声明主键为自增字段,但在duckdb略微复杂一点,需要先创建一个sequence:
1 2 3 4 5 6 7 8 | |
也就是,我们要先创建一个sequence,然后在创建表的主键时,声明其缺省值来自于nextval()函数。在往表中写入数据时,我们需要忽略PersonId。
渐进式构建查询¶
SQL语法很强大,但是它有时候很复杂且冗长。熟悉pandas的人知道,dataframe中的查询也可以很复杂,我们可以一步步构建查询,并查看中间结果以保证过程是正确的,这样一来,学习pandas也就变得简单。
现在,duckdb把这个能力借了过来。它在Python客户端中提供了Relational API来提供这一能力。
Info
duckdb为多种语言提供了接口。但是,在Python接口中提供了最强大的功能。
现在我们就来演示这个渐进式查询:
1 2 | |
第一行语句就构建了一个关系(relation)。它没有select!这是duckdb对sql语法的一种简化。当我们熟悉这种语法后,我们会发现,"select * from ..."这种传统的表达式实在是太啰嗦了。
第一行语句并不会执行,只有当我们调用r.show()时,它才被真正求值。
Info
如果是在jupyter中,情况会有所不同。下面的语句会被立即求值:
1 | |
1 | |
我们可以接着构建:
1 2 | |
可以看出,跟使用pandas差不多,但它的表达式语法是sql的,方法名也更接近sql的关键字。
在第一行,我们把select放在了from之后。这是duckdb的一个语法创新。在第二行中,这个表达式完全是SQL的表达式。我们在上一篇文章中介绍过,pandas是不支持这个语法的。
如果我们更熟悉pandas语法,是不是可以将数据读取后,存入dataframe(比如通过read_csv, read_sql)后,再来执行类似的查询?Yes and No。pandas无法处理超过内存的数据。所以,如果数据量比较大,duckdb的API的优势就显示出来了。
示例中演示了字符串匹配。duckdb有丰富的函数支持,包括字符串切片、正则表达式匹配。不过,这是一个比较特殊的场景,所以没有看到关于性能方面的报告。
Relational API另一个强大的使用场景是用在join、intersect上:
1 2 3 4 | |
这里的语法非常简练、更加易懂(甚至比pandas的join)。无论是构建子查询还是CTE,都会比较繁琐易错,但基于Relational API,这一切都能得到化简,并且很容易基于中间结果进行调试。下面是一个子查询的例子:
1 | |
我们可以很容易地将其分解为:
1 2 3 | |
如此一来,如果我们非常擅长SQL,则仍然可以编写复杂的SQL语句交给duckdb执行;如果只能写一些简短的SQL语句,我们仍然可能通过Relational API将它们组装成为复杂的SQL。
Note
在Relational API中,不能使用prepared parameter。
时间序列运算和窗口函数¶
在量化中,我们要处理的数据常常具有时间序列特征,常常要基于滑动窗口进行统计运算,比如最大最小值、平均值等等。在pandas中提供了rolling函数来实现滑动窗口。在duckdb中,我们实现它的方式是基于over和一系列的window函数。
我们以发电厂数据为例:
下面的语句将生成一个每日生产电力的7日移动平均:
1 2 3 4 5 6 7 8 9 | |
我们还可以通过window命令来定义命名窗口,以便可以复用它们以增强性能:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
上面的示例中,我们还看到了partition语法。每一个over子句(windowing)中,都隐藏了一个partition(如果没有使用partition语法),或者多个partition(如果使用了partition)。然后在每个partition内部,通过 range, preceding,following 等函数,定义一个个滑动的frame,最后,聚合运算就发生在这些frame上。
QUALIFY语法¶
这是个比较新的SQL语法,数年前由Teradata引入,随后被Oracle, snowflake, bigquery使用。它解决了这样的问题:如何取每个分组的某个列的前几名(或者其它条件)及它对应的整行数据?
在可以使用pandas的地方,这个问题比较简单:
1 2 3 | |

如果有别的条件,我们可以在groupby之后,使用apply和lambda函数来过滤。
在标准SQL中要完成上述任务,必须使用子查询,先选择出分组后满足条件的行ID,再从原表中查询返回这些行的全部数据。这个语句比较复杂,但使用qualify,我们的查询可以简化为:
1 2 3 4 | |
上述语句查询了每个ID最大的2个value值,并返回整行数据。over函数定义了窗口函数,在其中我们又通过partition将表按id划分成独立的“子表”,order by 就按value,对子表进行排序,并且每个partition内部产生行号。最后,我们通过qualify语法,获取行号前2的记录,就得到了满足要求的结果。
duckdb的荷兰方言¶
duckdb对标准SQL中的繁琐之处提出了一些改进。比如我们之前提到的省略'select *',直接使用'from tbl'这样的语法。
在量化研究中,我们的因子库常常是一张很宽的表,其中会有一些列有相似的列名字。比如,我们可能把RSI指标的30分钟、日线和周线都作为因子的一列。
有时候,我们可能希望同时选择这样三列,此时就可以使用它的Dynamic column select能力。比如'select columns('RSI_*') from alpha101'
如果我们的RSI因子都以RSI开头,再跟上不同的参数,这样就可以一次性将它们都选择出来。
duckdb为标量函数提供了链式调用,比如:
1 2 3 4 5 6 7 8 | |
还有很多好玩的功能,在他们的博客文章《even friendlier sql with duckdb》中有介绍。
duckdb的究竟是什么?¶
duckdb提供了与许多数据库、数据源的接口,在很多示例中,我们看到可以使用duckdb,基于这些数据进行分析,特别是对csv文件和parquet文件。当我们这样使用duckdb时,我们实际上是只使用它的分析引擎。
要最有效地利用duckdb的功能与强大的性能,我们最好将数据导入为duckdb自己的存储格式 -- 这是一个基于文件的数据库。它是基于列存储的和压缩的,类似于parquet,但duckdb的存储超越了parquet,允许存储多个表和视图,支持ACID,支持表的更改和列添加,而无需重写文件。因此,当我们把parquet文件导入为duckdb数据库时,大约会增加20%的磁盘空间占用。
当然,duckdb也有自己的局限。比如,不能使用多进程写数据库。
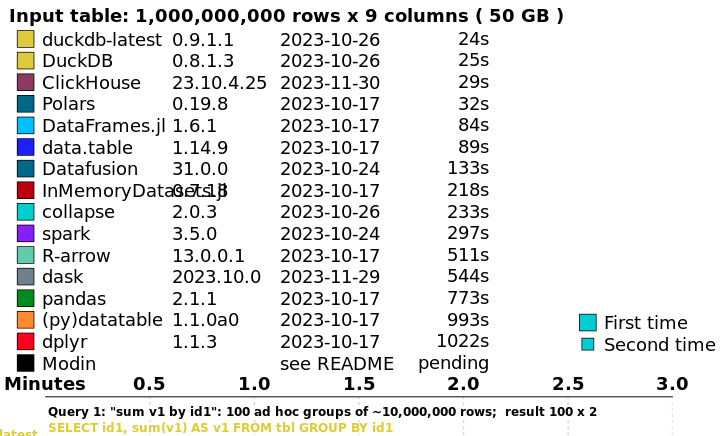
性能¶
作为量化人,不得不使用duckdb的原因之二(之一是asof join),是它的性能。在H2O.ai的排名中,在最吃性能的group by和join上,从0.5G,到5GB和50GB的计算中,duckdb都排在第一,紧随其后的是clickhouse和porlars。当然,我们无论如何都会使用clickhouse,两者的使用场景是不一样的。
不过,数据库性能测试的基准是TPC-DS测试。根据Fivetran CEO的测试,duckdb在存储文件大小小于250GB时,性能优于最好的商业数据库,但在1TB数据集时(此时使用32核心CPU和128GB内存),它的性能会落后不少。
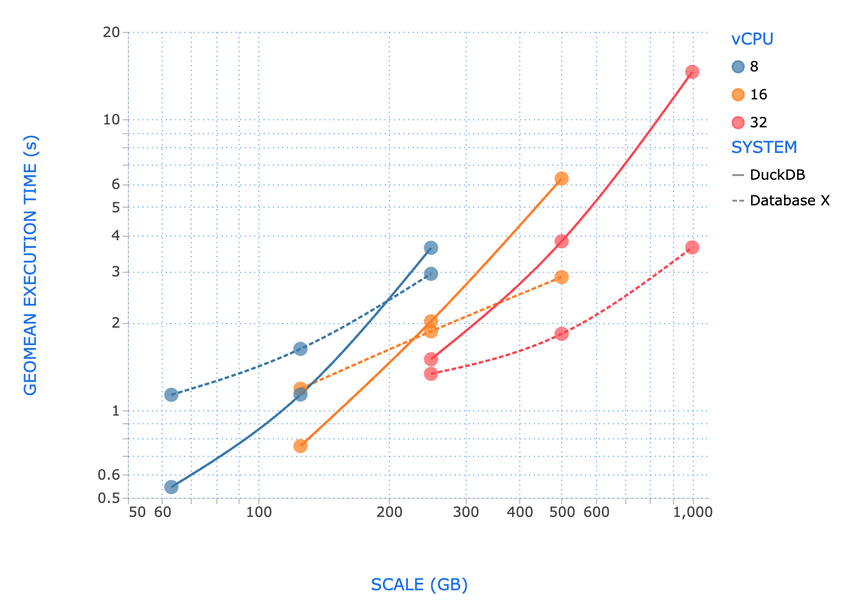
不过,这项测试的意义是让我们知道,至少duckdb可以容纳1TB左右的数据。但是它表现最好的区间是小于100GB,因此,duckdb可能仍然不适合来存储tick级别的行情数据。
在notebook中使用duckdb¶
在notebook中我们可以直接使用duckdb的Python API来进行查询。不过,我们也可以使用JupySQL这个扩展,来直接运行SQL查询,并实现可视化。
我们通过下面的命令来安装JupySQL:
1 | |
在使用jupysql之前,我们需要加载它:
1 | |
接下来就是建立连接。如果我们使用的是文件存储:
1 | |
然后就可以在接下来的cell中,使用cell magic语法了:
1 2 3 4 5 6 7 8 | |
这比我们使用python API会更方便一点,因为可以自由地缩进和换行。在使用sqlite时,我常常会用sqlite browser来查看程序生成的数据表,但是我们也可以完全只用JupySQL。
结论¶
作为量化人,我强烈推荐你使用duckdb作为个人使用的数据库工具。它完全替代和胜出了sqlite3。它是基于列存储和向量运算的,其性能超过了clickhouse和porlars。
一句话,如果你需要在一个只有16GB内存的机器上,分析100GB的数据,只考虑duckdb。