不能求二阶导的metrics
不是好的objective
Quote
最消耗你的东西,不是别人,而是自己的念头。人生之苦,苦在执着。人生之难,难在放下。强大不是对抗,而是接受。一念放下,万般自由。
To accept the things I cannot change,
the courage to change the things I can,
and the wisdom to know the difference
接上一篇。
今天我们要分析 MAPE 这个函数在论文中的使用。以此为契机,适当深入一点机器学习的原理,讲以下两个知识点:
2. XGBoost模型,因子数据是否要标准化
损失函数与度量函数¶
在机器学习中,有两类重要的函数,一类是目标函数(objective function),又称损失函数(loss function);一类是度量函数(metrics)。

损失函数用于模型训练。在训练过程中,通过梯度下降等方法,使得损失函数的值不断减小,直到无法继续下降为止,模型就训练完成。
训练完成之后的模型,将在test数据集上进行测试,并将预测的结果与真实值进行对比。为了将这个对比过程数值化,我们就引入了度量函数(metrics)。
在sklearn中,提供了大量的损失函数和度量函数。下图列举了部分Sklearn提供的损失函数和度量函数:
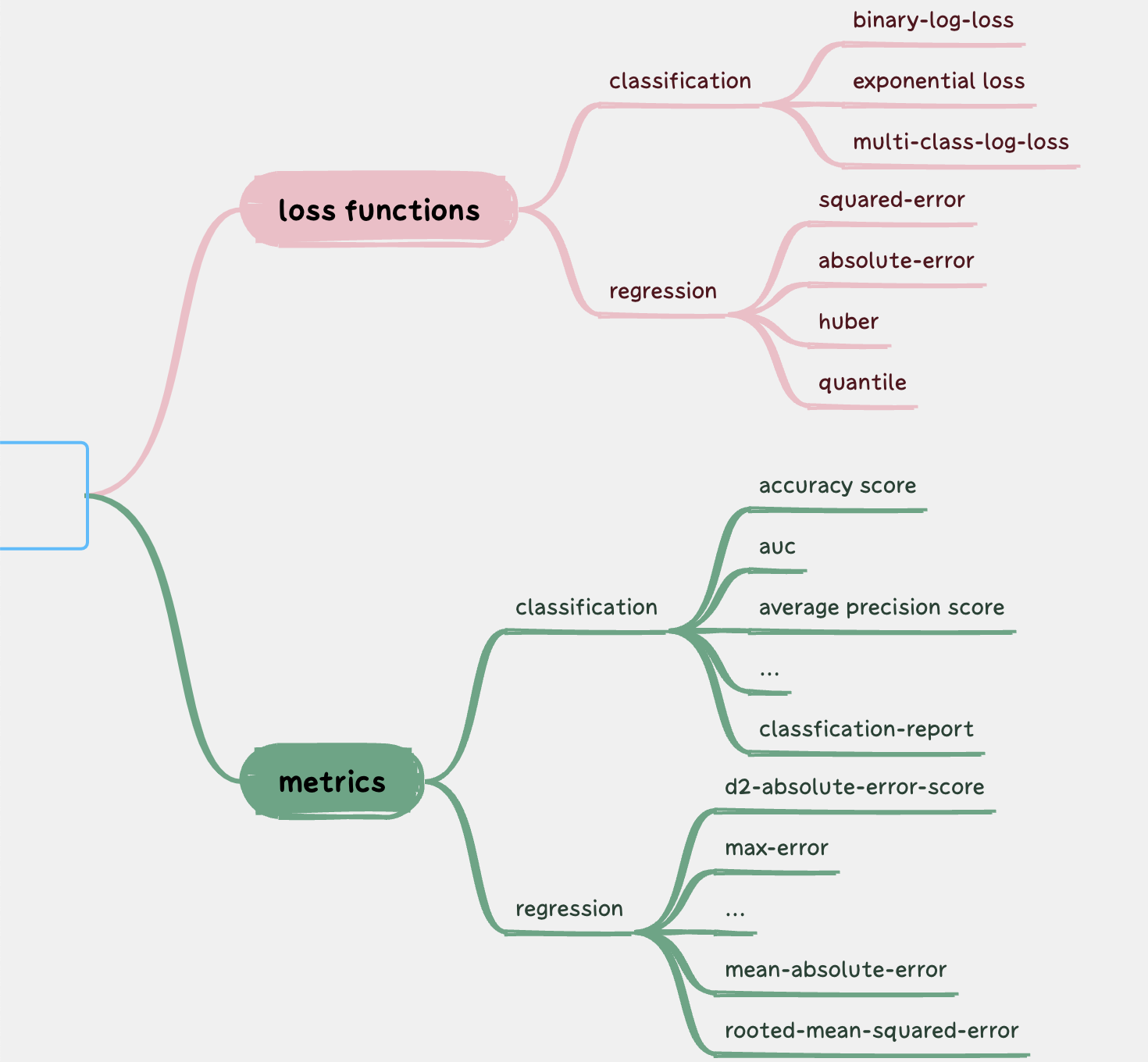
可以看出,度量函数的个数远多于损失函数,这是为什么呢?
在论文中,论文作者并没有披露他通过xgboost训练的具体过程,只是说直接使用了xgboost的database,这个表述有点奇怪,我们可以理解为在参数上使用了XGBoost的默认值好了。但是他重点提到了使用MAPE,从过程来看,是在把MAPE当成度量函数进行事后评估。
在XGBoost中,如果没有特别指定目标函数,那么默认会使用带正则惩罚的RMSE(rooted mean square error)函数。RMSE也可以作为度量函数,在论文中,作者没有使用RMSE作为度量函数,而是选择了MAPE(mean absolute percentage error),原因何在?如果MAPE在这个场景下比RMSE更好,又为何不在训练中使用MAPE?
看上去无论目标函数也好,度量函数也好,都要使得预测值与真实值越接近越好。既然都有这个特性,为什么还需要区分这两类函数呢?
要回答这些问题,就要了解XGBoost的训练原理,核心是:它是如何求梯度下降的。
XGBoost:二阶泰勒展开¶
XGBoost是一种提升(Boosting)算法,它通过多个弱学习器叠加,构成一个强学习器。每次迭代时,新的树会修正现有模型的残差,即预测值与真实值之间的差异。这个差异的大小,就由目标函数来计算。
在XGBoost中,多个弱学习器的叠加采用了加法模型,即最终的预测是所有弱学习器输出的加权和。这种模型允许我们使用泰勒展开来近似损失函数,从而进行高效的优化。
XGBoost对目标函数的优化是通过泰勒二阶展开,再求二阶导来实现的。使用二阶导数,XGBoost可以实现更快速的收敛,因为它不仅考虑了梯度的方向,还考虑了损失函数的形状。
正是由于XGBoost内部优化原理,决定了我们选择目标函数时,目标函数必须是二阶可导的。
RMSE是二阶可导的,但MAPE不是:MAPE从定义上来看,它的取值可以为零,在这些零值点附近连一阶导都不存在,就更不用说二阶导了。下图是MAPE的公式:
$$
\text{MAPE} = 100\frac{1}{n}\sum_{i=1}^{n}\left|\frac{\text{实际值} - \text{预测值}}{\text{实际值}} \right| $$
当预测值与实际值一致时,MAPE的值就会取零。
如何选择目标函数?¶
选择MAPE作为度量函数,不仅仅是便于在不同的模型之间进行比较,在金融领域它还有特殊的重要性:
我们更在乎预测值与真实值之间的相对误差,而不是绝对误差。在交易中,百分比才是王者。正因为这个原因,如果在训练时,能够使用MAPE作为目标函数,这样预测出来的准确度,要比我们通过RSME训练出来的准确度,更接近实际应用。
这就是在具体领域,我们改进算法的一个切入点。已经有人发明了被称为SMAPE的损失函数,它的公式是:
$$
\text{SMAPE} = \frac{100}{n} \sum_{t=1}^n \frac{\left|F_t-A_t\right|}{(|A_t|+|F_t|)/2} $$
到目前为止,sklearn还没有提供这个函数,但我们可以自己实现,并通过sklearn的make_scorer方法接入到sklearn系统中:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Question: 既然训练中不能使用MAPE,那么论文在测试中,又为何要使用MAPE呢?
答案其实很简单,是为了便于在多个模型之间进行比较。在论文作者的算法中,每支股票都必须有自己的模型。由于每支股票的绝对价格不一样,因此,它们的RSME是不一样的,而MAPE相当于一个归一化的指标,从而可以在不同的模型之间进行比较,最终选择出误差最小的模型对应的股票,纳入策略股池。
但我们前面也提到过,论文作者的这个模型没有意义,改用分类模型会好一些。如果改用分类模型的话,损失函数也不再是RSME了,度量函数也不能是MAPE了。
标准化¶
论文中还提到,在训练之前,他将因子数据进行了标准化。
实际上,这也是没有意义的一步。因为XGBoost是决策树模型,它是通过特征值的比较来进行分裂和划分数据的,显然,分裂点的比较,并不依赖数据的量纲,因此,标准化就没有意义,反而可能带来精度损失问题,得不偿失。
Hint
如果因子数据使用单精度浮点数储存,那么如果两个小数只在小数点的第7位数字之后才产生差异,这两个数字在比较时,实际上是一样的。如果我们在进行标准化时,把两个原来有大小差异的数字,缩放到了只在第7位数字之后才出现差异,就产生了精度损失。
当然,事情也不能一概而论。XGBoost使用正则化来控制树的复杂度,包括对叶节点的权重进行L2正则化。如果你在训练XGBoost模型时,损失函数加了正则惩罚,而特征未经过标准化,正则化的效果可能会变差。
另外,论文中的方法是,每支股票一个模型,但如果只用一个模型,但拿1000支股票的数据来训练1000次呢?显然,这个时候,就必须要提前进行标准化了。否则,收敛会很困难(当然,即使使用了标准化,也不保证就能收敛。能否收敛,要看众多股票是否真的具有同样的特征到标签的映射关系)。这并不是XGBoost的要求,而是根据我们使用XGBoost的方法带来的额外要求。
结论¶

对多数量化人来说,我们不可能像陈天奇那样自己撸一个机器学习框架出来,因此,要用同样的模型,做出更优的结果,就只能在数据标注、目标函数、评估函数和参数调优等方面下功夫了。这往往既需要有较深的领域知识,也要对具体的模型原理有一定的了解。
最后,博主的新书《Python高效编程实践指南》(机工出版)已经上架。作为量化人,要提升自己的工程水平,这本书是不二之选。自荐一下。