量化股票投资起手式
指数增强之
指数成份股信息挖掘
周一,巴菲特二季度大幅减仓、持有现金量超历史的消息,重创了全球股市。
在感叹巴菲特的智慧之余,我们能否深入一步,向股神学点东西?
其实,巴菲特通过每一年的股东大会,已经向我们传递了相当多的投资经验和理念。
今天我们从巴菲特的一则赌约说起。这则赌约是 2006 年,巴菲特在股东大会上提出的:一只简简单单跟踪美股市场的基金,能够击败任何一位自信满满的对冲基金经理。
巴菲特是对的。
不过,我们今天不谈如何跟踪指数 -- 这是各种指增策略已经在做的事情 -- 我们来探讨如何挖掘指数成分股信息。
先看指数编制数据。我们从万得拿到了历年各大股指,上证 50,沪深 300,中证 500 和 1000 的编制目录,导出为 4 个 excel 表,如下所示:
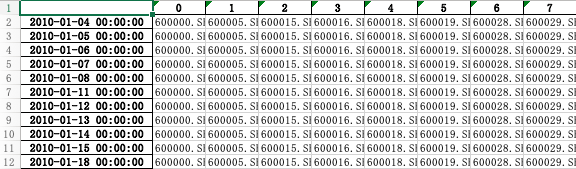
这里展示的是上证 50 的编制数据。这是一个 3000 多行,50 列的数据。索引是交易日,单元格值则是每个交易日成分股的代码。
其它几个 excel 表也是一样的格式,只不过列数不同而已。
首先,我们分析成份股变动情况。具体做法是,选定一个指数,遍历每一行,并且与上一行进行比较,把差异记录下来进行进一步分析。这一部分代码比较简单,我们就不演示了。
然后我们发现一个重要的结论。
科创板正跑步进入宽基指数¶
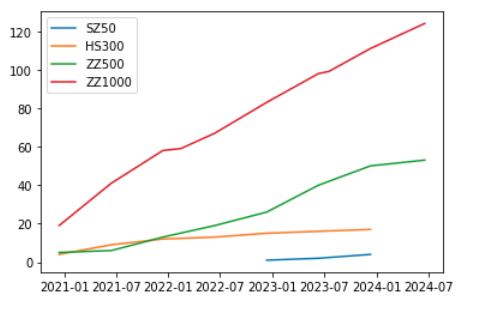
这张图显示了各个宽基指数纳入科创板个股的情况。
我们看到,中证 1000 从 2021 年 1 月起纳入科创板指数,到今年 7 月,已纳入 124 支,占比超过 10%;中证 500 也是一样,从 2021 年 1 月纳入,现在纳入 53 支,占比也超过了 10%。
中证 50 范围窄一些,对市值要求高,调入困难一点,不过到今年初,也纳入了 3 家。
联想到中国制造 2025 计划和发展新质生产力,这个结论既意外,也在情理之中。
奇怪的背离¶
有了第一个发现,我们自然就很好奇,科创板个股纳入指数后,表现如何?
在回答这个问题之前,作为量化科普,我们先抛出一个问题,如何评估个股纳入指数后的表现?
一般来说,可以从搜索指数、成交量来进行评估,但是这两种方法的缺陷是,与收益无关,因此不够直观。这里我们给出两种方法供探讨。
第一,取得个股纳入指数前一个月、后一个月、60 交易日、120 交易日的涨跌幅,与市场进行比较。
第二,将上述指标进行排名,查看排名的变化。以收益降序排名为例,如果排名下降,则说明个股纳入指数后,表现优于市场。
Question
按理说个股纳入指数之后的表现评估,是个很常见的事,而且也便于学术研究,应该有一些相关论文。可惜博主不够博,读论文太少,简单搜了一下,没有找到。欢迎留言指点。
按照这个思路,我们以中证 1000 为例,找出科创板个股纳入指数的日期,分别是 2020 年 12 月 14 日, 2021 年 6 月 15 日,...,2023 年 12 月 21 日等。
我们先看 2020 年 12 月 14 日,把这一天所有个股,从前一个月、到后 120 个交易日的行情数据取出,计算前一个月涨幅(prev),后一个月涨幅 ("20D")、后 60 个交易日涨幅 ("60D")、后 120 个交易日涨幅 ("120D"),分别对这些列进行排序,分别计为 rank_prev, rank_20, rank_60 和 rank_120。
我们使用的排序方法是 pandas 自带的函数:
1 2 | |
method 的作用是,万一存在多个相同值时,让 pandas 自动选择一个排名。
这样我们就得到了在 12 月 14 日这一天,所有个股的前一个月收益和远期收益及其排名。接下来,我们用当天进入中证 1000 的科创板个股筛选出一个子表,分别计算各项均值。
在 pandas 中,从一个 DataFrame 中,选择列值在某个集合中的所有行,可以用以下语句:
1 | |
这里假设 df 是包含所有个股的总表,includes 则是 12 月 14 日纳入中证 1000 的科创板个股。
语法的要点是,如果 pandas 的某个列是字符串类型,那么它就有 str 这个对象,通过过该对象我们可以调用很多字符串的方法,也包括这里的 contains 方法。
contains 方法支持按正则表达式匹配,因此,我们通过 join 方法,将 includes 中的所有元素用竖线(|)连接起来,作为正则表达式的匹配字符串,这样就选择出来所有新纳入中证 1000 的个股。
Tip
在正则表达式中,竖线 | 表示逻辑“或”(OR)运算。这意味着如果正则表达式中出现了 A|B,那么它会匹配 A 或者 B。
为了便于比较,我们对两个 dataframe 求均值,再进行合并,最后绘图。
1 2 3 4 5 6 7 8 9 | |
这里 df 仍然是包含所有个股的总表。代码中多次使用了转置T,这是我们通过pandas内置函数,对两个系列进行比较,绘制柱状图的关键。
最终,我们得到 2020 年 12 月 14 日,中证 1000 中新纳入的科创板个股表现如下:
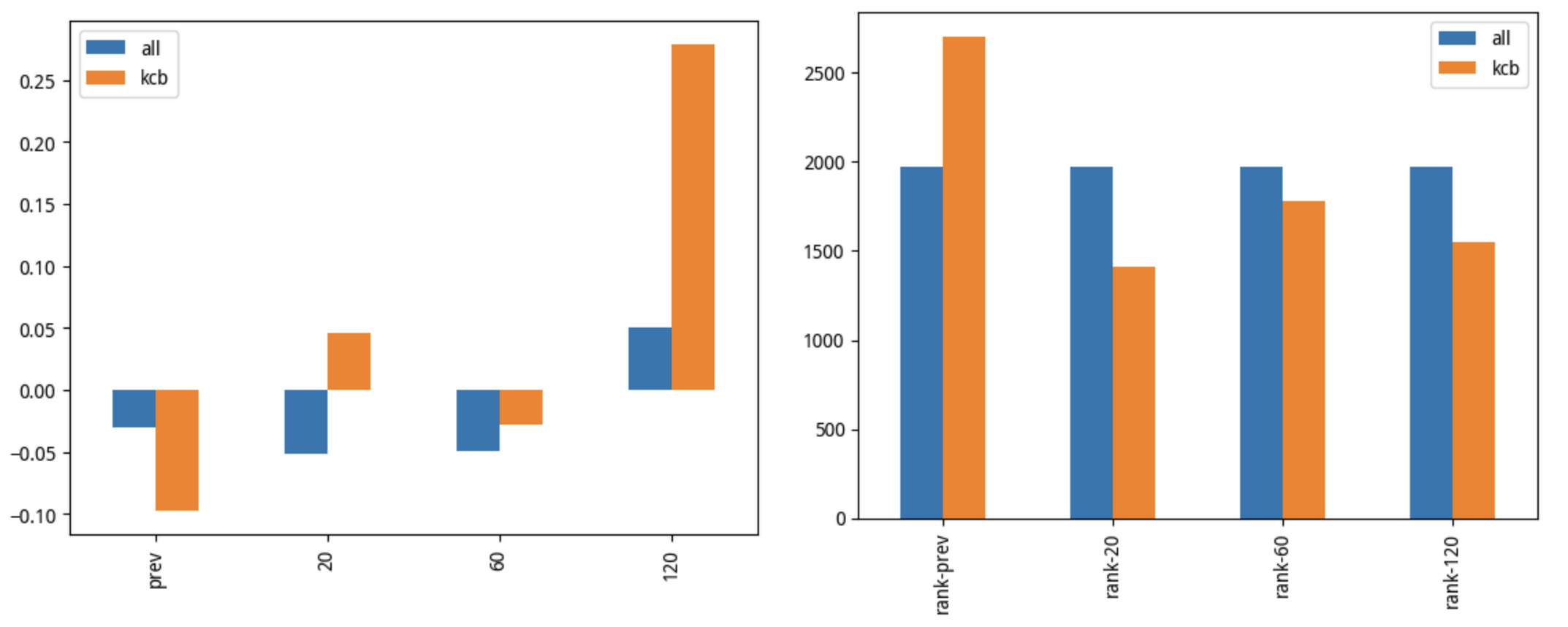
左图是收益对照图。从左图可以看出,在纳入指数前,这些个股的跌幅大于市场;在纳入指数之后,这些个股的表现都优于市场。
右图是排名对照图。从右图可以看出,在纳入指数后,这些个股的排名都相对于市场有所前移,也就是表现优于市场。
但是,不要被这个结论所欺骗。下图是去年底纳入中证 1000 的科创板个股表现:
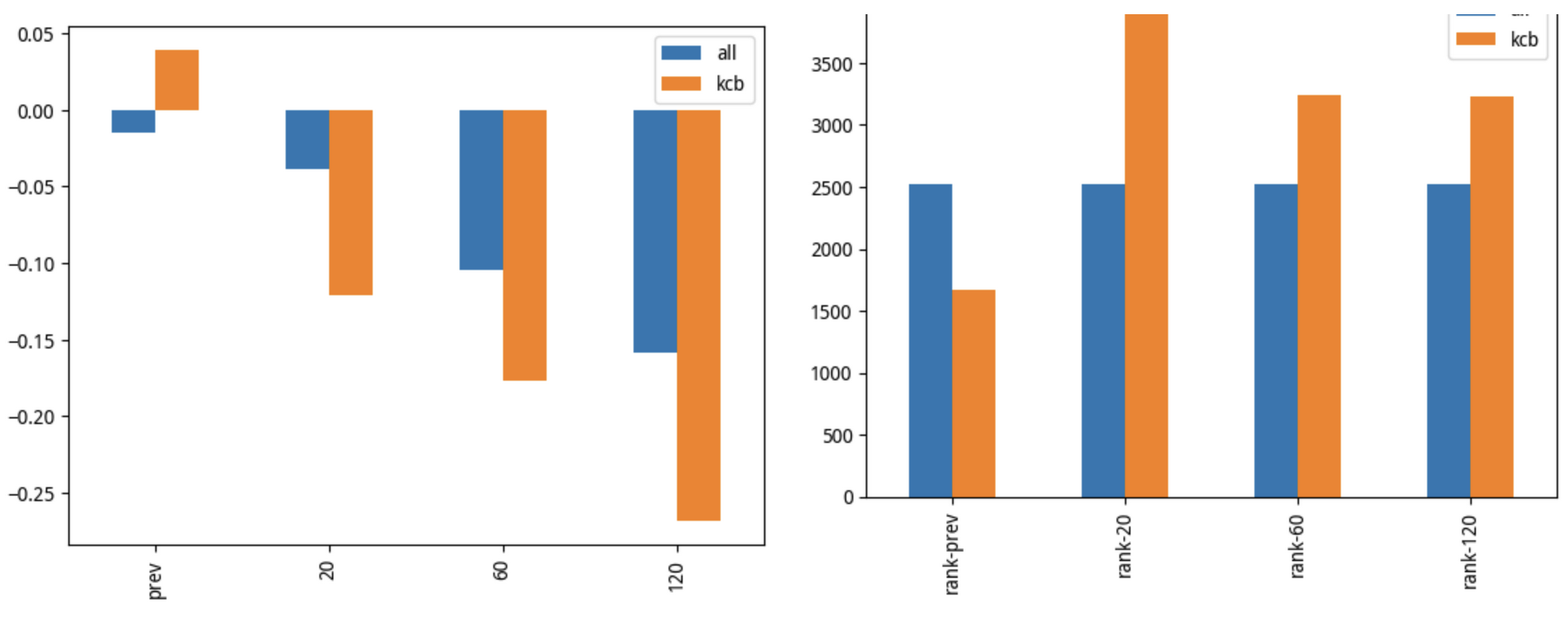
这是典型的相关性不等于因果性的另一个例证。
Tip
只要有足够多的数据,我们就能把相关性和因果性区分开来。除非,这些数据都只是高维空间在低维上的投影。丢失的信息,就是丢失了。
一般来说,个股纳入指数,往往会得到被动配置,从而首先在短期收益上有所提升;其次,能进入指数的个股,往往是优质标的,所以也更能得到长线资金的青睐,这也是巴菲特敢于打赌的原因所在--无它,就是这些股票更优秀。
但是,科创板个股最主要的归类仍然是科创板,所以它们受科创板本身的走势影响更大。
不过,科创板开板已经快 5 年,今年 10 月就要庆祝讲话 5 周年。毫无疑问,随着宽基指数加快纳入科创板个股,证券市场对新质生产力的支持,正逐渐体现出来。所以,无论科创板过去的表现如何,至少,对科创板的研究已经刻不容缓了。
声明:本文只是通过数据分析,发现了一种政策趋向,结论不一定正确,也不构成任何投资建议。