[0818] QuanTide Weekly
本周要闻¶
- 全球猴痘病例超1.56万,相关美股 GeoVax Labs收涨110.75%
- 央行发布重要数据,7月M2同比增长6.3%,M1同比下降6.6%
- 7月美国CPI同比上涨2.9%,零售销售额环比增长1%
- 证券时报:国企可转债的刚兑信仰该放下了
下周看点¶
- 周三,ETF期权交割日。以往数据表明,ETF期权交割日波动较大。
- 周三和周四,分别有3692亿和5777亿巨量逆回购到期。央行此前宣传将于到期日续作。
- 周二,上交所和中证指数公司发布科创板200指数
- 游戏《黑神话:悟空》正式发售,多家媒体给出高分
本周精选¶
- OpenBB实战!如何轻松获得海外市场数据?
- 贝莱德推出 HybridRAG,用于从财务文档中提取信息,正确率达100%!
本周要闻详情¶
- 世界卫生组织14日宣布,猴痘疫情构成“国际关注的突发公共卫生事件”。今年以来报告猴痘病例数超过1.56万例,已超过去年病例总数,其中死亡病例达537例。海关总署15日发布公告,要求来自疫情发生地人员主动进行入境申报并接受检测。相关话题登上东方财富热榜,载止发稿,达到107万阅读量,远超第二名(AI眼镜)的63万阅读量(新华网、东方财富)
- 央行13日发布重要数据,显示7月末M2余额303.31万亿元,同比增长6.3%;M1余额同比下降6.6%,M0同比增长12%。其中M1连续4个月负增长,表明企业活期存款下降,有些还在逐步向理财转化(第一财经)
- 今年7月美国CPI同比上涨2.9%,环比上涨0.2%,核心CPI同比上涨3.2%,同比涨幅为2021年4月以来最低值,但仍高于美联储设定的2%长期通胀目标。(新华网)
- 美国7月零售销售额环比增长1% 高于市场预期,是自2023年1月以来的最高值,汽车、电子产品、食品等销售额均增长。经济学家认为,美国经济将实现“软着陆”,在通胀“降温”的同时而不进入衰退。(中国新闻网)
- 纳斯达克指数一周上涨5.29%,道指一周上涨2.94%,再涨2%将创出历史新高。
- 证券时报:近日,某国企公告其发行的可转债到期违约,无法兑付本息,成为全国首例国企可转债违约,国企刚兑的信仰被打破。在一个成熟市场,相关主体真实的经营和财务状况,决定了其金融产品的风险等级。投资者在进行资产配置时,应该重点考量发行人的经营和财务状况,而不是因为对方是某种身份,就进行“拔高”或“歧视”。首例国企可转债违约的案例出现了,这是可转债市场的一小步,更是让市场之手发挥作用、让金融支持实体经济高质量发展的一大步。
长期以来,可转债是非常适合个人和中小机构配置的一种标的。下有债性托底,上有股性空间,也是网格交易法的备选标的之一。
OpenBB实战!¶
你有没有这样的经历?常常看到一些外文的论文或者博文,研究方法很好,结论也很吸引人,忍不住就想复现一下。
但是,这些文章用的数据往往都是海外市场的。我们怎么才能获得免费的海外市场数据呢?
之前有 yfinance,但是从 2021 年 11 月起,就对内陆地区不再提供服务了。我们今天就介绍这样一个工具,OpenBB。它提供了一个数据标准,通过它可以聚合许多免费和付费的数据源。
在海外市场上,Bloomberg 毫无疑问是数据供应商的老大,产品和服务包括财经新闻、市场数据、分析工具,在全球金融市场中具有极高的影响力,是许多金融机构、交易员、分析师和决策者不可或缺的信息来源。不过 Bloomberg 的数据也是真的贵。如果我们只是个人研究,或者偶尔使用一下海外数据,显然,还得寻找更有性价比的数据源。
于是,OpenBB 就这样杀入了市场。从这名字看,他们是想做一个一个 Open Source 的 Bloomberg。
安装 openbb¶
通过以下命令安装 openbb:
1 | |
Tip
openbb 要求的 Python 版本是 3.11 以上。你最好单独为它创建一个虚拟环境。
安装后,我们有多种方式可以使用它。
使用命令行¶
安装后,我们可以在命令行下启动 openbb。

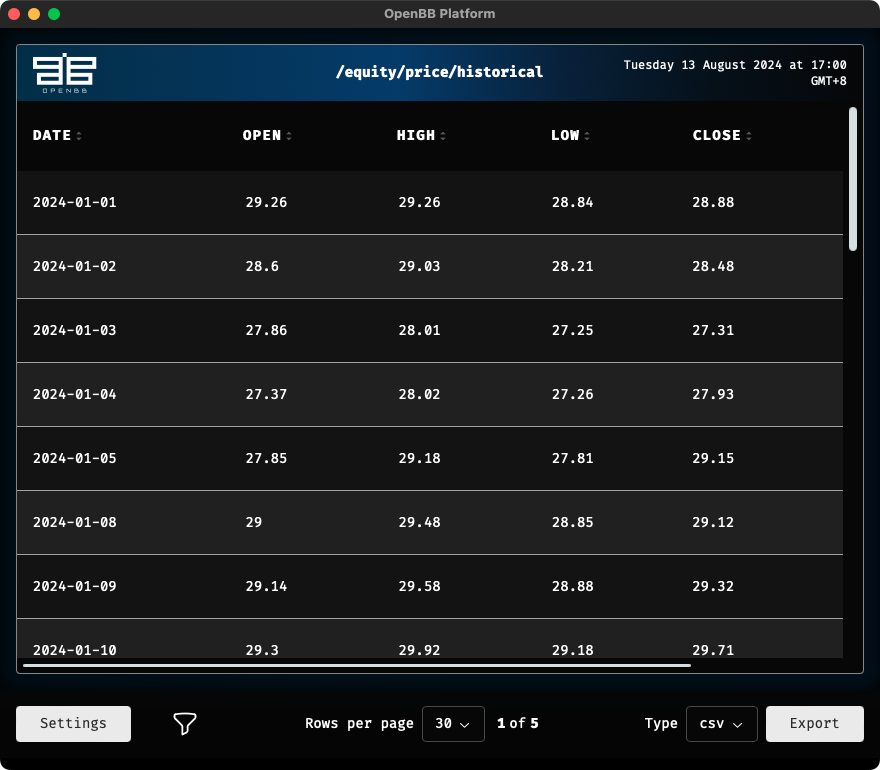
然后就可以按照提示,输入命令。比如,如果我们要获得行情数据,就可以一路输入命令 equity > price, 再输入 historical --symbol LUV --start_date '2024-01-01' --end_date '2024-08-01',就可以得到这支股票的行情数据。
openbb 会在此时弹出一个窗口,以表格的形式展示行情数据,并且允许你在此导出数据。
效果有点出人意料,哈哈。
比较有趣的是,他们把命令设计成为 unix 路径的模式。所以,在执行完刚才的命令之后,我们可以输入以根目录为起点的其它命令,比如:
1 | |
使用 Python¶
我们通过 notebook 来演示一下它的使用。
1 2 3 | |
这个 obb 对象,就是我们使用 openbb 的入口。当我们直接在单元格中输入 obb 时,就会提示我们它的属性和方法:
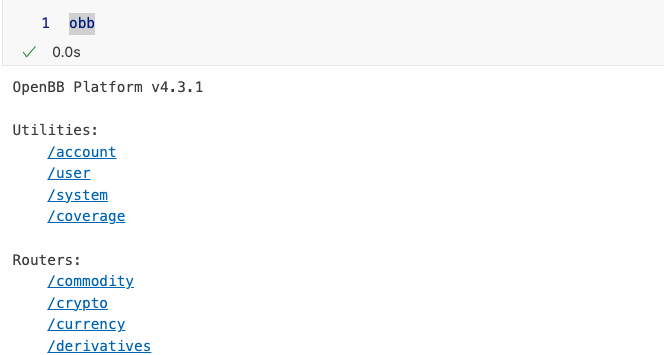
在这里,openbb 保持了接口的一致性。我们看到的内容和在 cli 中看到的差不多。
现在,我们演示一些具体的功能。首先,通过名字来查找股票代码:
1 2 3 | |
输出结果为:
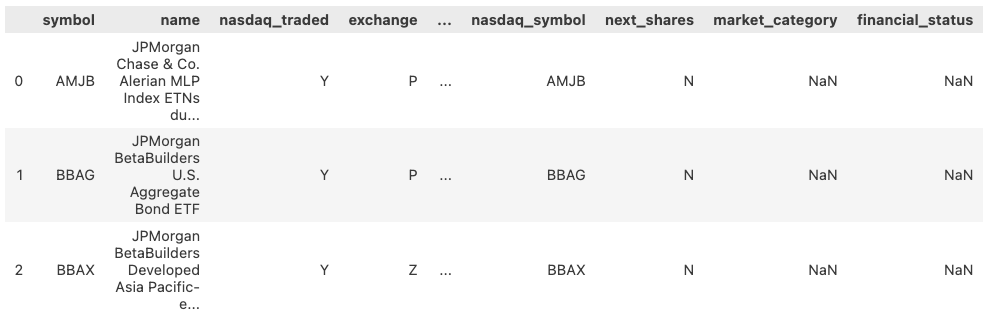
作为一个外国人,表示要搞清楚股票代码与数据提供商的关系,有点困难。不过,如果是每天都研究它,花点时间也是应该的。
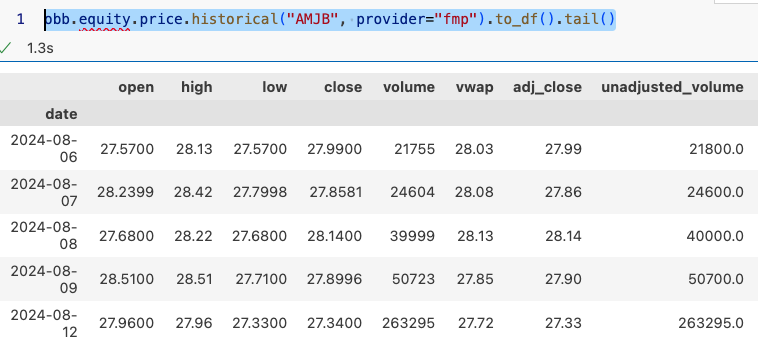
我们从刚才的结果中,得知小摩(我常常记不清 JPMorgan 是大摩还是小摩。但实际上很好记。一个叫摩根士丹利,另一个叫摩根大通。大通是小摩)的股票代码是 AMJB(名字是 JPMorgan Chase 的那一个),于是我们想查一下它的历史行情数据。如果能顺利取得它的行情数据,我们的教程就可以结束了。
但是,当我们调用以下代码时:
1 | |
出错了!提示 No result found.
使用免费、但需要注册的数据源¶
真实原因是 OpenBB 中,只有一个开箱即用的免费数据源 -- CBOE,但免费的 CBOE 数据源里没有这个股票。我们要选择另外一个数据源,比如 FMP。但是,需要先注册 FMP 账号(免费),再将 FMP 账号的 API key 添加到 OpenBB hub 中。
FMP 是 Financial Modeling Prep (FMP) 数据提供商,它提供免费(每限 250 次调用)和收费服务,数据涵盖非常广泛,包括了美国股市、加密货币、外汇和详细的公司财务数据。免费数据可以回调 5 年的历史数据。
Tip
OpenBB 支持许多数据源。这些数据源往往都提供了一些免费使用次数。通过 OpenBB 的聚合,你就可以免费使用尽可能多的数据。
注册 FMP 只需要有一个邮箱即可,所以,如果 250 次不够用,看起来也很容易加量。注册完成后,就可以在 dashboard 中看到你的 API key:
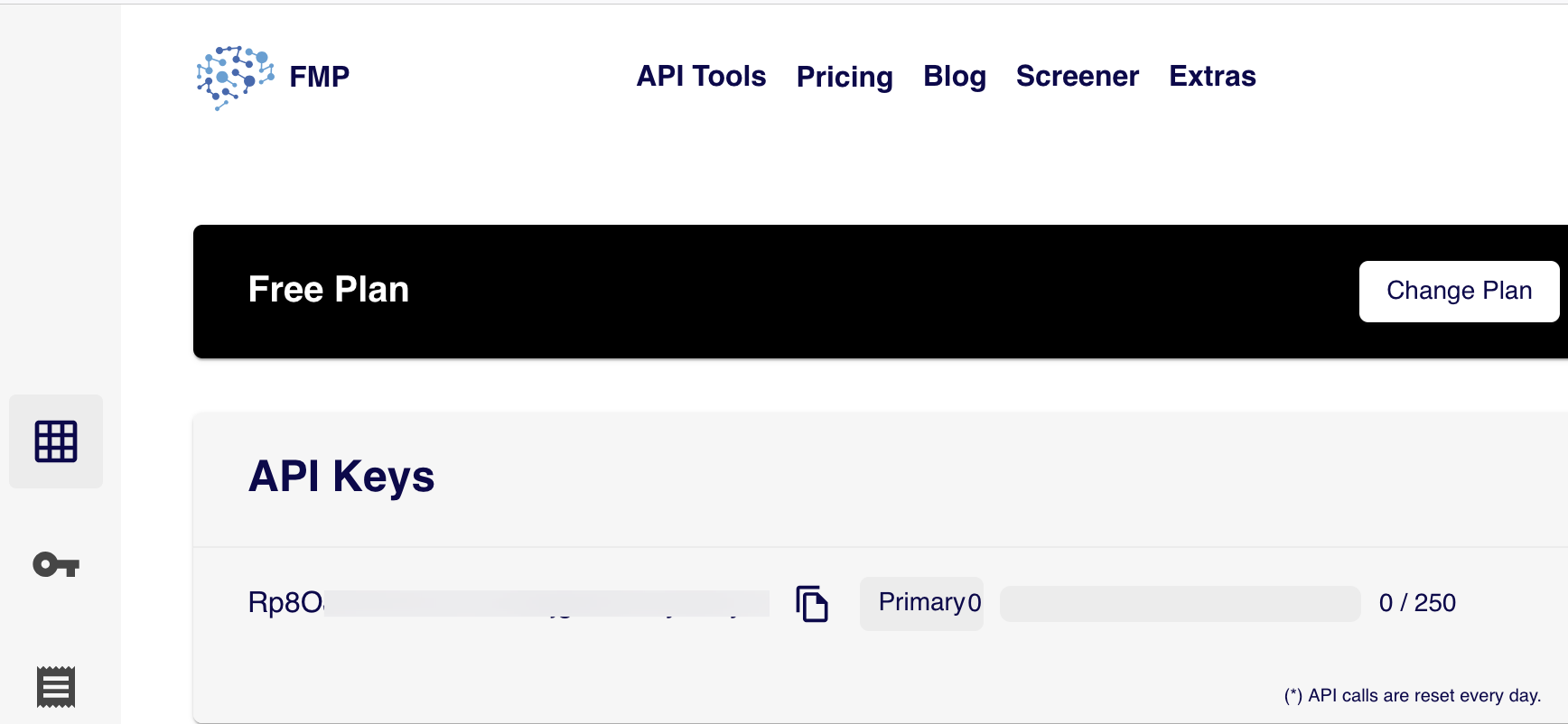
然后注册 Openbb Hub 账号,将这个 API key 添加到 OpenBB hub 中。
现在,我们将数据源改为 FMP,再运行刚才的代码,就可以得到我们想要的结果了。
1 | |
我们将得到如下结果:
换一支股票,apple 的,我们也是先通过 search 命令,拿到它的代码'AAPL'(我常常记作 APPL),再代入上面的代码,也能拿到数据了。
需要做一点基本面研究,比如,想知道 apple 历年的现金流数据?
1 | |
任何时候,交易日历、复权信息和成份股列表都是回测中不可或缺的(在 A 股,还必须有 ST 列表和涨跌停历史价格)。我们来看看如何获取股标列表和成份股列表:
1 2 3 4 5 6 7 8 9 10 11 12 | |
好了。尝试一个新的库很花时间。而且往往只有花过时间之后,你才能决定是否要继续使用它。如果最终不想使用它,那么前面的探索时间就白花了。
于是,我们就构建了一个计算环境,在其中安装了 OpenBB,并且注册了 fmp 数据源,提供了示例 notebook,供大家练习 openbb。
这个环境是免费提供给大家使用的。登录地址在这里,口令是: ope@db5d
贝莱德推出 HybridRAG¶
大模型已经无处不在,程序员已经发现,使用大模型来生成代码非常好用 -- 但这有一个关键,就是程序员知道自己在干什么,并且大模型生成的代码是否正确。
但涉及到金融领域,事情就变得复杂起来。没有人知道大模型生成的答案是否正确,而且也不可能像程序员那样进行验证 -- 这种验证要么让你错过时机,要么让你损失money。
从非结构化文本,如收益电话会议记录和财务报告中,提取相关见解的能力对于做出影响市场预测和投资策略的明智决策至关重要,这一直是贝莱德全球最大的资产管理公司的核心观点之一。
最近他们的研究人员与英伟达一起,推出了一种称为 HybridRAG 的新颖方法。该方法集成了 VectorRAG 和基于知识图的 RAG (GraphRAG) 的优点,创建了一个更强大的系统,用于从财务文档中提取信息。
HybridRAG 通过复杂的两层方法运作。最初,VectorRAG 基于文本相似性检索上下文,这涉及将文档划分为较小的块并将它们转换为存储在向量数据库中的向量嵌入。然后,系统在该数据库中执行相似性搜索,以识别最相关的块并对其进行排名。同时,GraphRAG 使用知识图来提取结构化信息,表示财务文档中的实体及其关系。通过合并这两种上下文,HybridRAG 可确保语言模型生成上下文准确且细节丰富的响应。
HybridRAG 的有效性通过使用 Nifty 50 指数上市公司的财报电话会议记录数据集进行的广泛实验得到了证明。该数据集涵盖基础设施、医疗保健和金融服务等各个领域,为评估系统性能提供了多样化的基础。研究人员比较了 HybridRAG、VectorRAG 和 GraphRAG,重点关注忠实度、答案相关性、上下文精确度和上下文召回等关键指标。
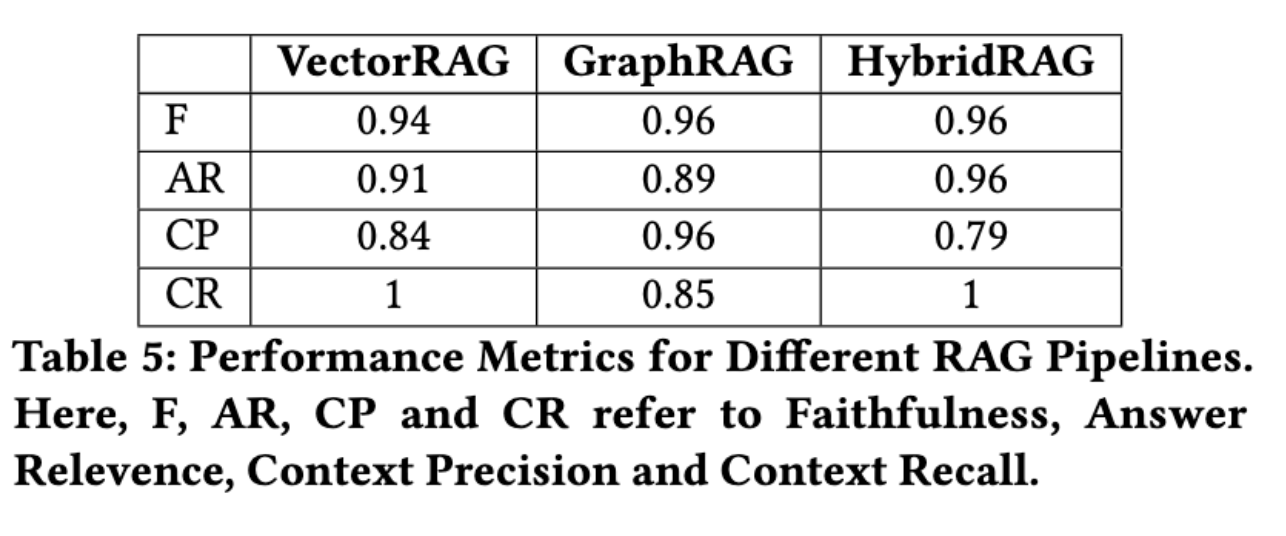
分析结果表明,HybridRAG 在多个指标上均优于 VectorRAG 和 GraphRAG。 HybridRAG 的忠实度得分为 0.96,表明生成的答案与提供的上下文相符。关于答案相关性,HybridRAG 得分为 0.96,优于 VectorRAG (0.91) 和 GraphRAG (0.89)。
GraphRAG 在上下文精确度方面表现出色,得分为 0.96,而 HybridRAG 在上下文召回方面保持了强劲的表现,与 VectorRAG 一起获得了 1.0 的满分。这些结果强调了 HybridRAG 在提供准确、上下文相关的响应,同时平衡基于矢量和基于图形的检索方法的优势方面的优势。