本周要闻¶
- 大涨!沪指本周大涨12.8%,沪深300上涨15.7%。
- 首份市值管理指引文件出炉,明确指数成分股与破净股的市值管理
- 长江证券:银行、地产、建筑和非银等板块或更有可能受益于破净公司估值提升计划
下周看点¶
- 周一:财新发布9月PMI数据
- OpenAI10月1日起举办2024年度DevDay活动
- 周二(10月1日)至10月7日休市
本周精选¶
- 连载!量化人必会的 Numpy 编程(5)
- A股本周全线大涨。消息面上,周二国新办举行新闻发布会,介绍金融支持经济高质量发展有关情况。盘前降准、降低存量房贷利率提振市场信心,盘中,资本市场密集释放重磅利好:证监会研究制定“并购6条”,创设首期3000亿元股票回购增持再贷款,首期5000亿元规模证券基金保险公司互换便利操作,支持汇金公司等中长期资金入市,正在研究创设平准基金。
消息来源:东方财富 - 财联社9月28日:近日,A股首份市值管理指引文件出炉,明确了指数成分股与破净股的市值管理具体要求。业内人士表示,市值管理新政策有助于被低估的优质资产进行重新定价,尤其是破净幅度较深但盈利能力稳定的央国企,可能存在价值重估空间,带来投资机遇。另有分析人士表示,而在破净的同时还具备高股息率的股票,更加值得投资者关注。
- 央行公开市场7天期逆回购操作利率调整为1.5%。本周央行还对存准金下调了0.5%。
Numpy量化应用案例[2]¶
动量和反转是最重要的量化因子。有很多种刻画动量的算法,但拟合直线的斜率无疑是最直观的一种。

在上面的图形中,如果两条直线对应着两支股票的均线走势,显然,你更愿意买入橘色的那一支,因为它的斜率更大,也就是涨起来更快一些。
人类的视觉有着强大的模式发现能力。我们很容易看出橙色点的上升趋势更强。但是,如果要让计算机也知道哪一组数据更好,则需要通过直线拟合,找出趋势线,再比较趋势线的斜率才能确定。直线拟合,或者曲线拟合(cureve fit),或者多项式拟合,都是线性回归问题。
在这一章中,我们就来讨论直线拟合的方法,并且要从最普通的实现讲到能提速百倍的向量化实现。
线性回归与最小二乘法¶
如何从一堆随机的数字中,发现其中可能隐藏的、最能反映它们趋势的直线呢?这个问题从大航海时代开始起就困扰着科学家们。
在那个时代,水手们需要通过星相来确定自己的纬度(经度则是通过日冕来计算的),这就需要基于人类的观测,准确地描述天体的行为。
在解决天体观测所引起的误差问题时,法国人阿德里安.玛丽.勒让德(Adrien Marie Legendre)最先发现了最小二乘法(1805年),此后,高斯在1809年发表的著作《天体运动论》中也提出了这一方法。最终,他在1829年,给出了最小二乘法是线性回归最佳拟合的理论证明。这一证明被称为高斯-马尔科夫定理。
Info
在勒让德与高斯之间,存在着一场最小二乘法发现权之争。这场争战一点也不亚于牛顿与莱布尼茨关于微积分发现权之争。不过,勒让德提出最小二乘法时,还只是一种猜想,其理论证明是由高斯完成的。勒让德是18世纪后期,与拉格朗日、拉普拉斯齐名的数学家,被称为三L(取自三个人的名字)。
所谓直线拟合(或者线性回归),就是要在由(x,y)构成的点集中,找到一条直线,使得所有点到该直线的距离的平方和最小。在Numpy中,我们最常用的方法是通过Polynomial.fit来进行拟合:
1 2 3 4 5 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
在很多教程上,我们看到在Numpy中进行多项式回归,使用的是polyfit。但实际上从1.4起,我们应该使用polynomial模块下的类和方法。polyfit被看成是过时的接口。要注意,尽管polynomial被设计为polyfit等函数的替代物,但在行为上有较大不同。
关于Polynomial.fit,需要注意我们传入了deg=1和domain=[]两个参数。
指定deg=1,是因为我们希望将由(x,y)表示的点集拟合成为直线;如果希望拟合成为二次曲线,则可以指定deg=2,高次曲线依次类推。
domain是可以省略的一个参数。省略它之后,对我们后面通过fitted(x)求预测直线并没有影响,但是,它对我们要求的斜率(第19行)会有影响。如果在这里我们省略domain = []这个参数,我们得到的系数会是 [2.47, 4.57]。这将与我们造数据时使用的[0.05, 2]相去甚远。而当我们指定domain = []后,我们将看到拟合直线的系数变回为我们期望的[0.05, 2]。
Tip
我们也可以这样调用fit:
1 2 3 | |
或者:
1 2 3 | |
convert是一个对domain和window进行平移和缩放的转换函数。
线性回归是非常常用的技巧,在scipy, sklearn和statsmodels等库中都有类似的实现。
正因为如此,求价格或者均线的斜率因子,在技术上是一件轻而易举的事。
但是,如果我们要求移动线性回归呢?这可能就需要一点技巧了。
移动线性回归¶
移动线性回归是指对一个时间序列\(T\)和滑动窗口\(win\),计算出另一个时间序列\(S\),使得
最简单直接的实现是通过一个循环:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
这段代码计算了从第10个周期起,过去10个点的拟合直线的斜率,并且在曲线的转折点上,我们绘制了它的切线。这些切线,正是通过拟合直线的参数来生成的。
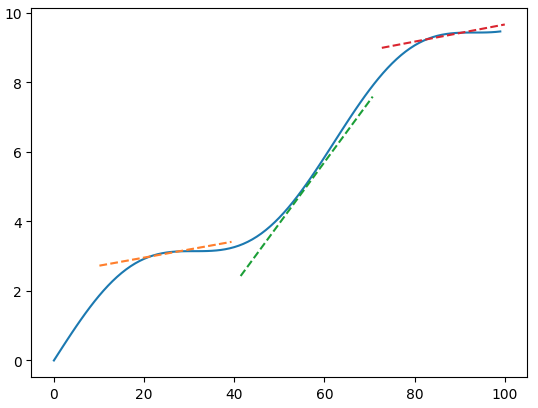
在这里,我们生成曲线的方法是使用了方程x + sin(x)。你会发现,这样生成的曲线,有几分神似股价的波动。这并不奇怪,股价的波动本来就应该可以分解成为一个直流分量与许多正弦波的叠加。直流分量反映了公司的持续经营能力,正弦波则反映了各路短炒资金在该标的上操作留下的痕迹。
回到我们的正题来。现在,我们去掉绘图功能,测试一下这段代码需要执行多长时间:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
90次循环,总共用去25ms的时间。考虑到A股有超过5000支股票,因此全部计算一次,这将会超过2分钟。
要加速这一求解过程,我们必须借助向量化。但是,这一次,再也没有魔法一样的API可以调用,我们必须挽起袖子,从理解底层的数学原理开始,做出自己的实现。
向量化¶
考虑到一个有m个点的线性回归,对其中的每一个点,都会有:
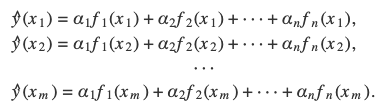
如果所有的点都落在同一条直线上,那么意味着以下矩阵方程成立:
这里\(A\)即为X,\(\beta\)为要求解的系数:
关于公式推导,可以见《Python programming and Numerical Methods - A Guide for Engineers and Scientists》
我们可以手动来验证一下这个公式:
1 2 3 4 5 6 7 8 9 10 11 | |
我们用两种方法分别求解了斜率,结果表明,在1e-2的绝对误差约束下,两者是相同的。
注意在第7行中, 我们使用了pinv这个奇怪的变量名。这是因为,在numpy.linalg中存在一个同名函数,正好就是计算\({(A^TA)}^{-1}A^T\)的。
不过,到现在为止,我们仅仅是完成了Polynomial.fit所做的事情。如果我们要一次性计算出所有滑动窗口下的拟合直线斜率,究竟要如何做呢?
注意,我们计算斜率,是通过一个矩阵乘法来实现的。在Numpy中,矩阵乘法天然是向量化的。在第7行中,pinv是一个(1,10)的矩阵,而y则是一个(10,)的向量。如果我们能把滑动窗口下,各组对应的pinv堆叠起来,并且y也堆叠起来成为一个矩阵,那么就能通过矩阵乘法,一次性计算出所有的斜率。
我们先从y看起。当我们对y = np.arange(5)按窗口为3进行滑动时,我们实际上是得到了这样一个矩阵:
要得到这个矩阵,我们可以使用fancy index:
1 2 3 4 5 | |
因此,我们要实现滑动窗口下的y的矩阵,只需要构建出这个fancy index矩阵即可。好消息是,fancy index矩阵非常有规律:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
如果你觉得这个方法难以理解的话,Numpy已经为我们提供了一个名为as_strided的函数,可以一步到位,实现我们要的功能,并且比上述方法更快(1倍):
1 2 3 4 5 6 7 8 9 | |
矩阵pinv由x产生。如果时间序列y有100个周期长,那么x的值将会是从0到99。
其中\([x0, x1, ..., x_{win-1}]\)对应\([y0, y1, ..., y_{win-1}]\), \([x1, x2, ..., x_{win}]\)对应\([y1, y2, ..., y_{win}]\),\([x_{-win}, x_{-win+1}, ... x_{-1}]\)对应\([y_{-win}, y_{-win+1}, ..., y_{-1}]\)。
因此,我们需要构照的系数矩阵\(A\)即:
1 2 | |
接下来的回归运算跟之前一样:
1 | |
完整的代码如下:
1 2 3 4 5 6 7 8 9 10 | |
这一版本,比之前使用Polynomial.fit加循环的快了100倍。你可能猜到了,这个100倍近似于我们循环的次数。这就是循环的代价。
现在,运用这里的方法,我们还可以加速别的计算吗?答案是显然的。如果你要快速计算5000支股票过去10天的的5日平均,在获取这些股票最近14天的股价之后,组成了一个(5000, 14)的矩阵\(A\)。现在,我们要做的就是将这个矩阵转换成为3维矩阵,然后再与一个卷积核做乘法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
我们通过下面的代码来测试它:
1
2
3
4
5
6
prices = np.array([
np.arange(0, 14),
np.arange(10, 24)
])
batch_move_mean(prices, 5)
¶
1 2 3 4 5 6 | |
输出为:
1 2 | |
正如我们期待的一样。但快如闪电。
题外话¶
要不要使用拟合趋势线作为一种动量因子?这是一个值得深入讨论的话题。斜率因子最大的问题,不是所有的时间序列,都有明显的趋势。从数学上看,如果拟合残差较大,说明该时间序列还没有形成明显的趋势,那么斜率因子就不应该投入使用。另一个问题就是线性回归的老问题,即个别outlier对拟合的影响较大。拟合直线究竟是应该使得所有点到该直线的距离和最小,还是应该使得大多数点到该直线的距离和更小(小于前者)?
结论¶
我们讨论了如何通过numpy来进行线性回归(直线拟合),并且介绍了最新的polynomial API。然后我们介绍了如何利用矩阵运算来实现向量化。
核心点是通过as_strided方法将数组升维,再对升维后的数组执行矩阵运算,以实现向量化。我们还用同样的思路,解决了一次性求5000支股票的移动均线问题。您还看到了像fancy index的实用性举例。这一章技巧较多,算是对前面章节的小结。
《因子投资与机器学习策略》开课啦!¶

目标清晰 获得感强¶

为什么你值得QuanTide的课程?¶
