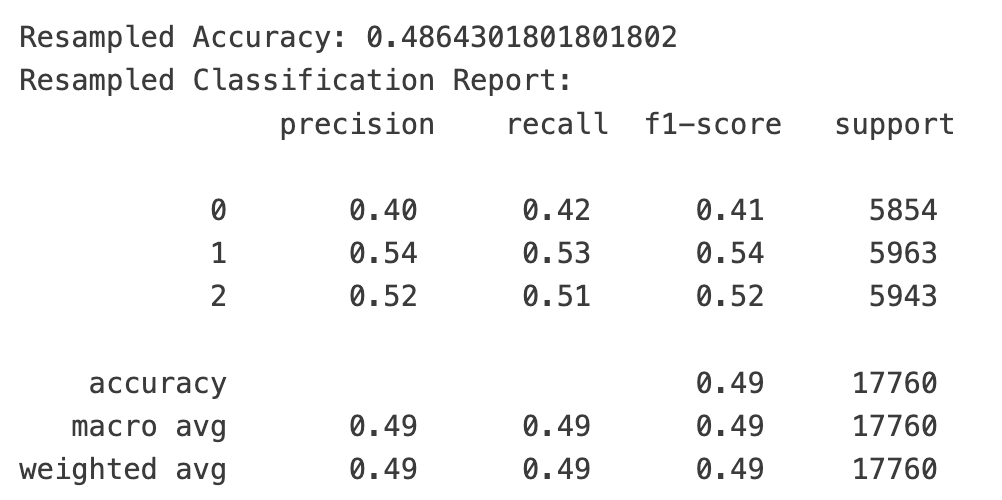
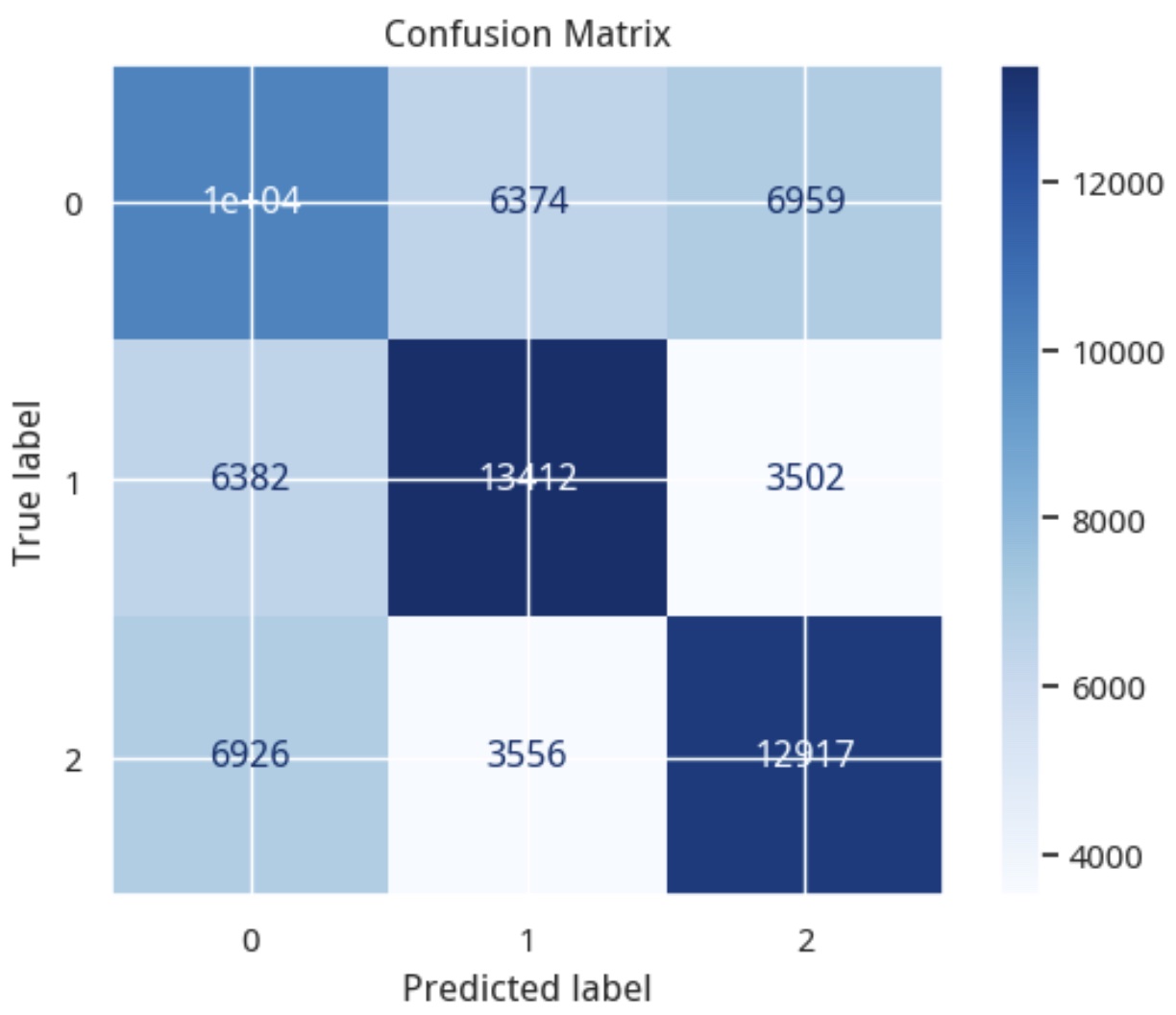
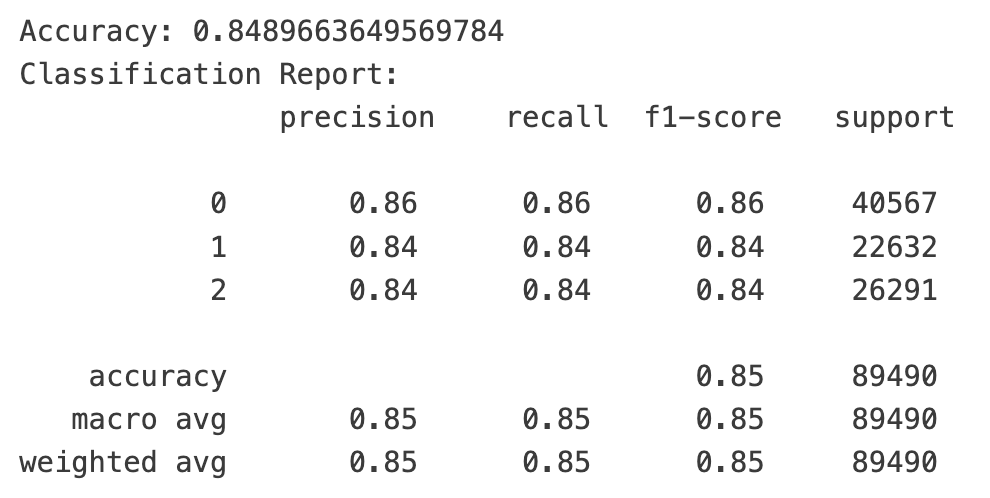
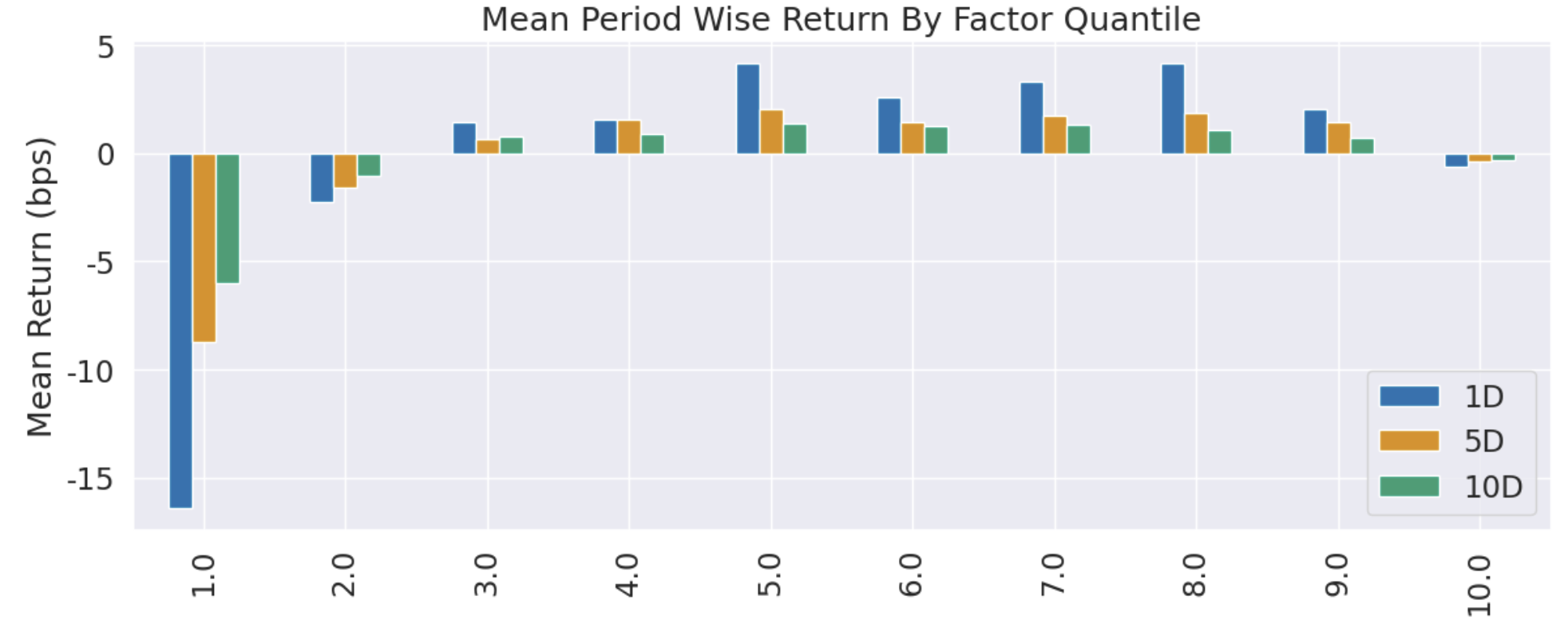
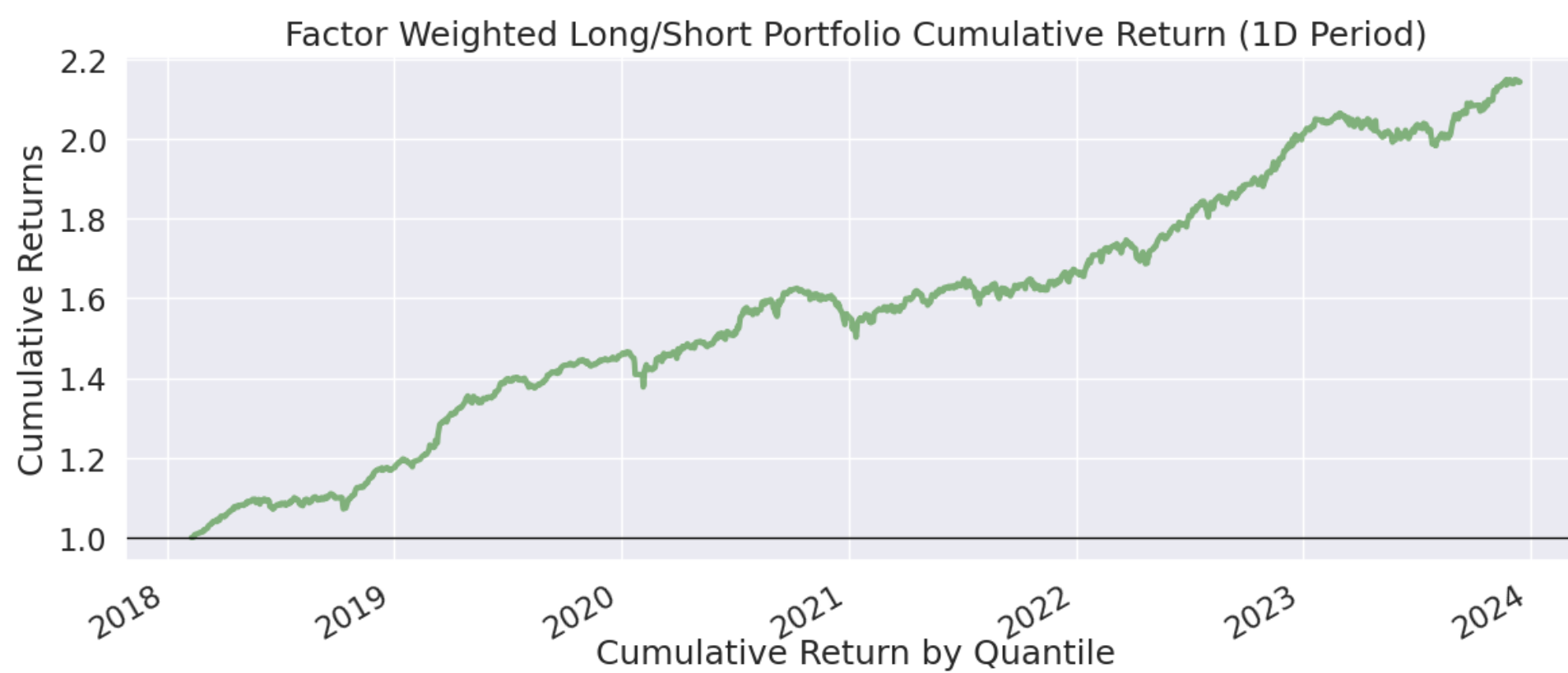
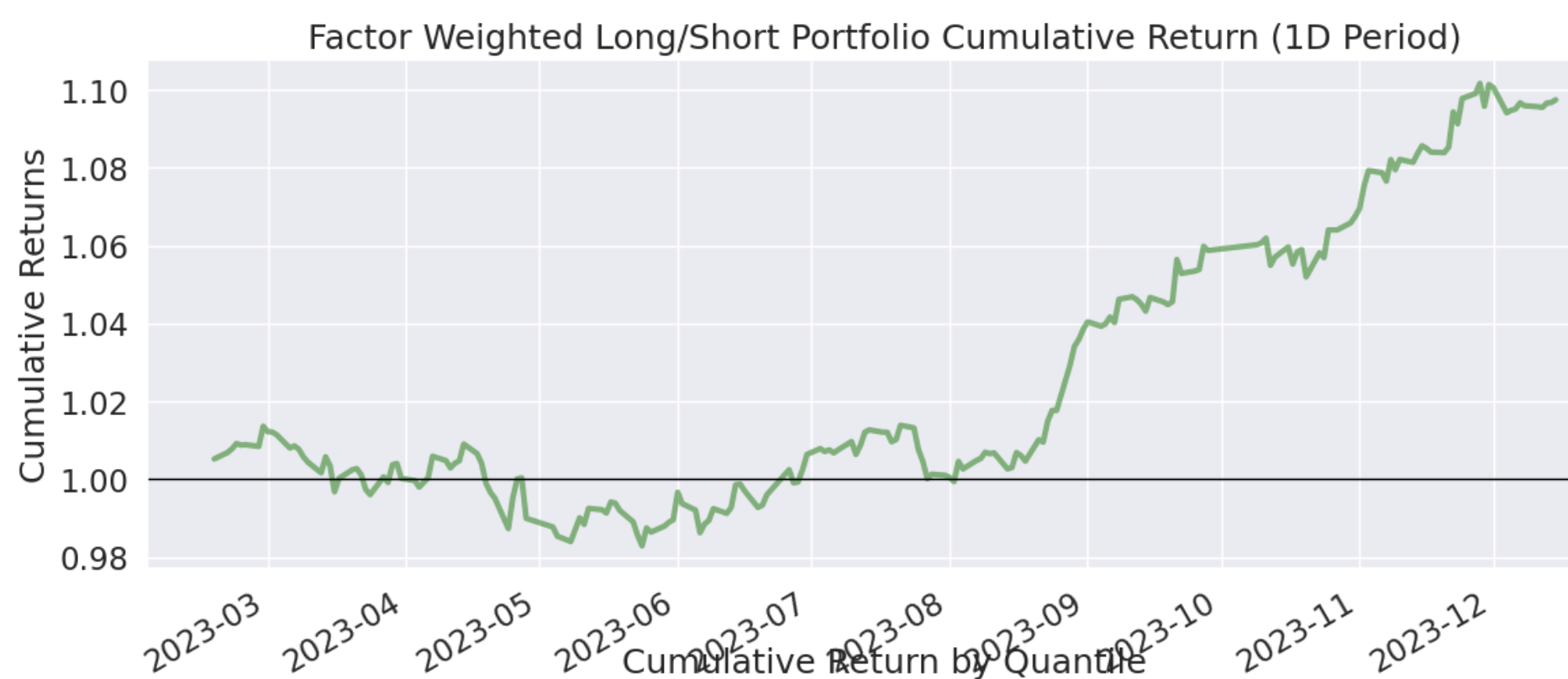
如果你去商场逛,你会发现,销量最好的店和最好的商品总是占据人气中心。对股票来说也是一样,被新闻和社交媒体频频提起的个股,往往更容易获得更大的成交量。
如果一支个股获得了人气,那它的成交量一定很大,两者之间有强相关关系。但是,成交量落后于人气指标。当一支个股成交量开始放量时,有可能已经追不上了(涨停)。如果我们能提前发现人气指标,就有可能获得提前介入的时机。
那么具体怎么操作(建模)呢?
我们首先讲解一点信息检索的知识,然后介绍如何运用统计学和信息检索的知识,来把上述问题模型化。
TF 是 Term Frequency 的意思。它是对一篇文档中,某个词语共出现了多少次的一个统计。IDF 则是 Inverse Document Frequency 的意思,大致来说,如果一个词在越多的文档中出现,那么,它携带的信息量就越少。
比如,我们几乎每句话都会用到『的、地、得』,这样的词几乎在每个语境(文档)中都会出现,因此就不携带信息量。新闻业常讲的一句话,狗咬人不是新闻,人咬狗才是新闻,本质上也是前者太常出现,所以就不携带信息量了。
最早发明 TF-IDF 的人应该是康奈尔大学的杰拉德·索尔顿(康奈尔大学的计算机很强)和英国的计算机科学家卡伦·琼斯。到今天,美国计算机协会(ACM)还会每三年颁发一次杰拉德·索尔顿奖,以表彰信息检索领域的突出贡献者。
TF-IDF 的构建过程如下:
假如我们有 3 篇文档,依次是:
- 苹果 橙子 香蕉
- 苹果 香蕉 香蕉
- 橙子 香蕉 梨
看上去不像文档,不过这确实是文档的最简化的形式--就是一堆词的组合(在 TF-IDF 时代,还无法处理词的顺序)。在第 1 篇文档中,橙子、香蕉和苹果词各出现 1 次,每个词的 TF 都记为 1,我们得到:
| TF_1 = {
'苹果': 1/3,
'香蕉': 1/3,
'橙子': 1/3,
}
|
在第二篇文档中,苹果出现 1 次,香蕉出现 2 次,橙子和梨都没有出现。于是得到:
| TF_2 = {
'苹果': 1/3,
'香蕉': 2/3,
}
|
第三篇文档中,TF 的计算依次类推。
IDF 实际上是每个词的信息权重,它的计算按以下公式进行:
\[
\text{IDF}(t) = \log \left( \frac{N + 1}{1 + \text{DF}(t)} \right) + 1
\]
- DF:每个词在多少篇文档中出现了。
- N 是文档总数,在这里共有 3 篇文档,所以\(N=3\)
- 公式中,分子与分母都额外加 1,一方面是为了避免 0 作为分母,因为\(DF(t)\)总是正的,另外也是一种 L1 正则化。这是 sklearn 中的做法。
这样我们可以算出所有词的 IDF:
\[
苹果 = 橙子 = \log \left( \frac{4}{2+1} \right) + 1 = 1.2876
\]
\[
梨 = \log \left( \frac{4}{1+1} \right) + 1 = 1.6931
\]
因为梨这个词很少出现,所以,一旦它出现,就是人咬狗事件,所以它的信息权重就大。而香蕉则是一个烂大街的词,在 3 篇文档中都有出现过,所有我们惩罚它,让它的信息权重为负:
\[
香蕉 = \log \left( \frac{4}{3+1} \right) + 1 = 1
\]
最后,我们得到每个词的 TF-IDF:
\[
TF-IDF=TF\times{IDF}
\]
这样我们以所有可能的词为列,每篇文档中,出现的词的 TF-IDF 为值,就得到如下稀疏矩阵:
|
苹果 |
香蕉 |
橙子 |
梨 |
| 文档 1 |
1.2876/3 |
1/3 |
1.2876/3 |
0 |
| 文档 2 |
1.2876/3 |
1/3 * 2 |
0 |
0 |
| 文档 3 |
0 |
1/3 |
1.2876/3 |
1.6931/3 |
在 sklearn 中,最后还会对每个词的 TF-IDF 进行 L2 归一化。这里就不手动计算了。
我们把每一行称为文档的向量,它代表了文档的特征。如果两篇文档的向量完全相同,那么它们很可能实际上是同一篇文章(近似。因为,即使完全使用同样的词和词频,也可以写出不同的文章。
比如,『可以清心也』这几个字,可以排列成『以清心也可』,也可以排列成『心也可以清』,或者『清心也可以』,都是语句通顺的文章。
插播一则招人启事,这是我司新办公地:
新场子肯定缺人。但这个地方还在注册中,所以提前发招聘信息,算是粉丝福利。
Info
急招课程助理(武汉高校,三个月以上实习生可)若干人。课程助理要求有一定的量化基础,能编辑一些量化方向的文章,热爱学习,有自媒体经验更好。
在实际应用中,我们可以使用 sklearn 的 TfidfVectorizer 来实现 TF-IDF 的计算:
1
2
3
4
5
6
7
8
9
10
11
12
13 | import pandas as pd
def jieba_tokenizer(text):
return list(jieba.cut(text))
d1 = "苹果橙子香蕉"
d2 = "苹果香蕉香蕉"
d3 = "橙子香蕉梨"
vectorizer = TfidfVectorizer(tokenizer = jieba_tokenizer)
matrix = vectorizer.fit_transform([d1, d2, d3])
df = pd.DataFrame(matrix.toarray(), columns = vectorizer.get_feature_names_out())
df
|
|
梨 |
橙子 |
苹果 |
香蕉 |
| 0 |
0.000000 |
0.619805 |
0.619805 |
0.481334 |
| 1 |
0.000000 |
0.000000 |
0.541343 |
0.840802 |
| 2 |
0.720333 |
0.547832 |
0.000000 |
0.425441 |
结果与我们手工计算的有所不同,是因为我们在手工计算时,省略了计算量相对较大的L2归一化。
从上面的例子可以看出,TF-IDF 是用来提取文章的特征向量的。有了这个特征向量,就可以通过计算余弦距离,来比较两篇文档是否相似。这可以用在论文查重、信息检索、比较文学和像今日头条这样的图文推荐应用上。
比如,要证明曹雪芹只写了《红楼梦》的前87回,就可以把前87回和后面的文本分别计算TF-IDF,然后计算余弦距离,此时就能看出差别了。
又比如,如果用TF-IDF分析琼瑶的作品,你会发现,如果去掉一些最重要的名词之后,许多她的文章的相似度会比较高。下面是对《还珠格格》分析后,得到的最重要的词汇及其TF-IDF:
| 紫薇: 0.0876
皇帝: 0.0754
尔康: 0.0692
皇后: 0.0621
五阿哥: 0.0589
容嬷嬷: 0.0573
小燕子: 0.0556
四阿哥: 0.0548
福晋: 0.0532
金锁: 0.0519
|
跟你的印象是否一致?但是,TF-IDF的分析方法,在量化交易中有何作用,目前还没有例证。
讲到这里,关于 TF-IDF 在量化交易中的作用,基本上就讲完了。因为,接下来,我们要跳出 TF-IDF 的窠臼,自己构建因子了!
根据 TF-IDF 的思想,这里提出一个 word-count 因子。它的构建方法是,通过 tushare 获取每天的新闻信息,用 jieba 进行分词,统计每天上市公司名称出现的次数。这是 TF 部分。
在 IDF 构建部分,我们做法与经典方法不一样,但更简单、更适合量化场景。这个方法就是,我们取每个词 TF 的移动平均做为 IDF。这个IDF就构成了每个词的基准噪声,一旦某天某个词的频率显著大于基准噪声,就说明该公司上新闻了!
最后,我们把当天某个词的出现频率除以它的移动平均的读数作为因子。显然,这个数值越大,它携带的信息量也越大,表明该词(也就是该公司)最近在新闻上被频频提起。
我们可以通过 tushare 的 news 接口来获取新闻。
这个方法是:
| news = pro.news(src='sina',
date=start,
end_date=end,
)
|
我们把获取的新闻数据先保存到本地,以免后面还可能进行其它挖掘:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39 | 请在本地尝试以下代码,不要在Quantide Reseach环境中运行!!
```python
def retry_fetch(start, end, offset):
i = 1
while True:
try:
df =pro.news(**{
"start_date": start,
"end_date": end,
"src": "sina",
"limit": 1000,
"offset": offset
}, fields=[
"datetime",
"content",
"title",
"channels",
"score"])
return df
except Exception as e:
print(f"fetch_new failed, retry after {i} hours")
time.sleep(i * 3600)
i = min(i*2, 10)
def fetch_news(start, end):
for i in range(1000):
offset = i * 1000
df = retry_fetch(start, end, offset)
df_start = arrow.get(df.iloc[0]["datetime"]).format("YYYYMMDD_HHmmss")
df_end = arrow.get(df.iloc[-1]["datetime"]).format("YYYYMMDD_HHmmss")
df.to_csv(os.path.join(data_home, f"{df_start}_{df_end}.news.csv"))
if len(df) == 0:
break
# tushare 对新闻接口调用次数及单次返回的新闻条数都有限制
time.sleep(3.5 * 60)
```
|
在统计新闻中上市公司出现的词频时,我们需要先给 jieba 增加自定义词典,以免出现分词错误。比如,如果不添加关键词『万科 A』,那么它一定会被 jieba 分解为万科和 A 两个词。
增加自定义词典的代码如下:
| def init():
# get_stock_list 是自定义的函数,用于获取股票列表。在 quantide research 环境可用
stocks = get_stock_list(datetime.date(2024,11,1), code_only=False)
stocks = set(stocks.name)
for name in stocks:
jieba.add_word(name)
return stocks
|
这里得到的证券列表,后面还要使用,所以作为函数返回值。
接下来,就是统计词频了:
1
2
3
4
5
6
7
8
9
10
11
12
13 | def count_words(news, stocks)->pd.DataFrame:
data = []
for dt, content, _ in news.to_records(index=False):
words = jieba.cut(content)
word_counts = Counter(words)
for word, count in word_counts.items():
if word in stocks:
data.append((dt, word, count))
df = pd.DataFrame(data, columns=['date', 'word', 'count'])
df["date"] = pd.to_datetime(df['date'])
df.set_index('date', inplace=True)
return df
|
tushare 返回的数据共有三列,其中 date, content 是我们关心的字段。公司名词频就从 content 中提取。
然后我们对所有已下载的新闻进行分析,统计每日词频和移动均值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 | def count_words_in_files(stocks, ma_groups=None):
ma_groups = ma_groups or [30, 60, 250]
# 获取指定日期范围内的数据
results = []
files = glob.glob(os.path.join(data_home, "*.news.csv"))
for file in files:
news = pd.read_csv(file, index_col=0)
df = count_words(news, stocks)
results.append(df)
df = pd.concat(results)
df = df.sort_index()
df = df.groupby("word").resample('D').sum()
df.drop("word", axis=1, inplace=True)
df = df.swaplevel()
unstacked = df.unstack(level="word").fillna(0)
for win in ma_groups:
df[f"ma_{win}"] = unstacked.rolling(window=win).mean().stack()
return df
count_words_in_files(stocks)
|
最后,完整的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61 | import os
import glob
import jieba
from collections import Counter
import time
data_home = "/data/news"
def init():
stocks = get_stock_list(datetime.date(2024,12,2), code_only=False)
stocks = set(stocks.name)
for name in stocks:
jieba.add_word(name)
return stocks
def count_words(news, stocks)->pd.DataFrame:
data = []
for dt, content, *_ in news.to_records(index=False):
if content is None or not isinstance(content, str):
continue
try:
words = jieba.cut(content)
word_counts = Counter(words)
for word, count in word_counts.items():
if word in stocks:
data.append((dt, word, count))
except Exception as e:
print(dt, content)
df = pd.DataFrame(data, columns=['date', 'word', 'count'])
df["date"] = pd.to_datetime(df['date'])
df.set_index('date', inplace=True)
return df
def count_words_in_files(stocks, ma_groups=None):
ma_groups = ma_groups or [30, 60, 250]
# 获取指定日期范围内的数据
results = []
files = glob.glob(os.path.join(data_home, "*.news.csv"))
for file in files:
news = pd.read_csv(file, index_col=0)
df = count_words(news, stocks)
results.append(df)
df = pd.concat(results)
df = df.sort_index()
df = df.groupby("word").resample('D').sum()
df.drop("word", axis=1, inplace=True)
df = df.swaplevel()
unstacked = df.unstack(level="word").fillna(0)
for win in ma_groups:
df[f"ma_{win}"] = unstacked.rolling(window=win).mean().stack()
return df.sort_index(), unstacked.sort_index()
stocks = init()
factor, raw = count_words_in_files(stocks)
factor.tail(20)
|
这里计算的仍然是原始数据。最终因子化要通过 factor["count"]/factor["ma_30"] 来计算并执行 rank,这里的 ma_30 可以替换为 ma_60, ma_250 等。
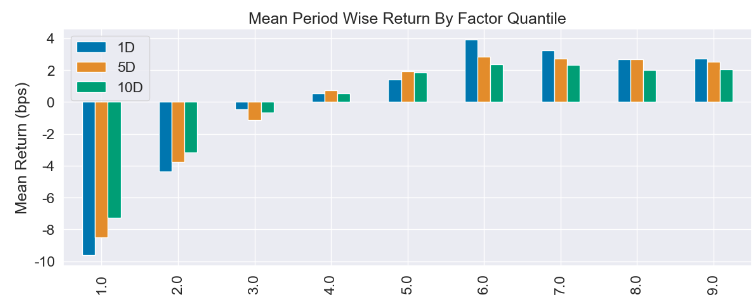
跟以往的文章不同,这一次我们没有直接得到好的结果。我们的研究其实多数时候都是寂寞的等待,然后挑一些成功的例子发表而已。毕竟,发表不成功的例子,估计意义不大(很少人看)。
但是这一篇有所不同。我们没有得到结果,主要是因为数据还在积累中。这篇文章从草稿到现在,已经半个月了,但是我仍然没能获取到 1 年以上的新闻数据,所以,无法准确得到每家公司的『基底噪声』,从而也就无法得到每家公司最新的信息熵。但要获得 1 年以上的数据,大概还要一个月左右的时间。所以,先把已经获得的成果发出来。
尽管没有直接的结果,但是我们的研究演示了对文本数据如何建模的一个方法,也演示了如何使用TF-IDF,并且在因子化方向也比较有新意,希望能对读者有所启发。
我们已经抓取的新闻数据截止到今年的 8 月 20 日,每天都会往前追赶大约 10 天左右。这些数据和上述代码,可以在我们的 quantide research 平台上获取和运行。加入星球,即可获得平台账号。