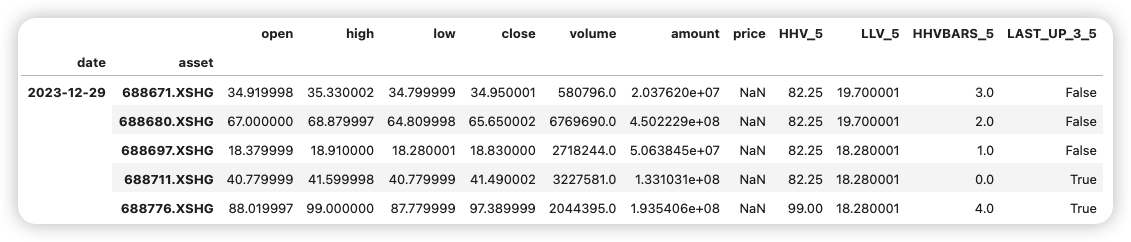
试过 Cursor 和 Trae 之后,我如何用 Augment 完成了一个复杂项目
常常有人问,真有人用 AI 完成过一个复杂的项目吗?
我!
在这个过程中,我感受到 Augment (也许不只是 Augment,而是 AI 辅助编程)强大的力量。它帮我省下很多个小时。如果你是一位秀发飘逸的美女程序员,你更是应该用它 -- 它指定能保住你的头发 -- 不过这一点对我来说已经无关紧要了。
为了完成匡醍量化课程的学员注册问题,最近我尝试了Cursor和 Trae,最终使用 Augment 来完成了这个项目。当然,我不想在这里争论类似于 PHP 是不是最好的编程语言的问题;所以,如果你对 Augment 不感兴趣,那也请多尝试其它 AI 编程工具!
今天这个令人疲倦、但最终峰回路转的下午,是促使我再加班一晚上写这篇文章的原因。Augment 的 Agent Auto 模式成为 Man of the Moment, 最终它把我拉出了泥潭,使得我可以赶上项目部署的 deadline,并且还可能有时间水一篇文章。
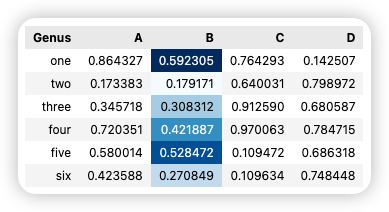
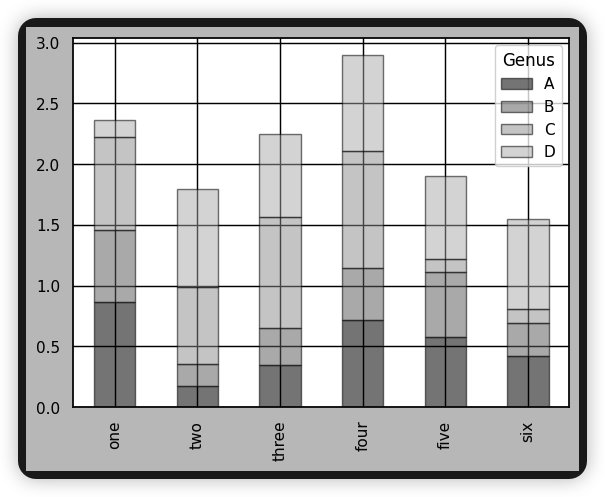
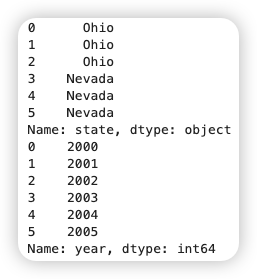
在我最近招聘员工的时候,我会抛出这样一张图,让候选人回答,你能从这张图中,得到哪些信息?
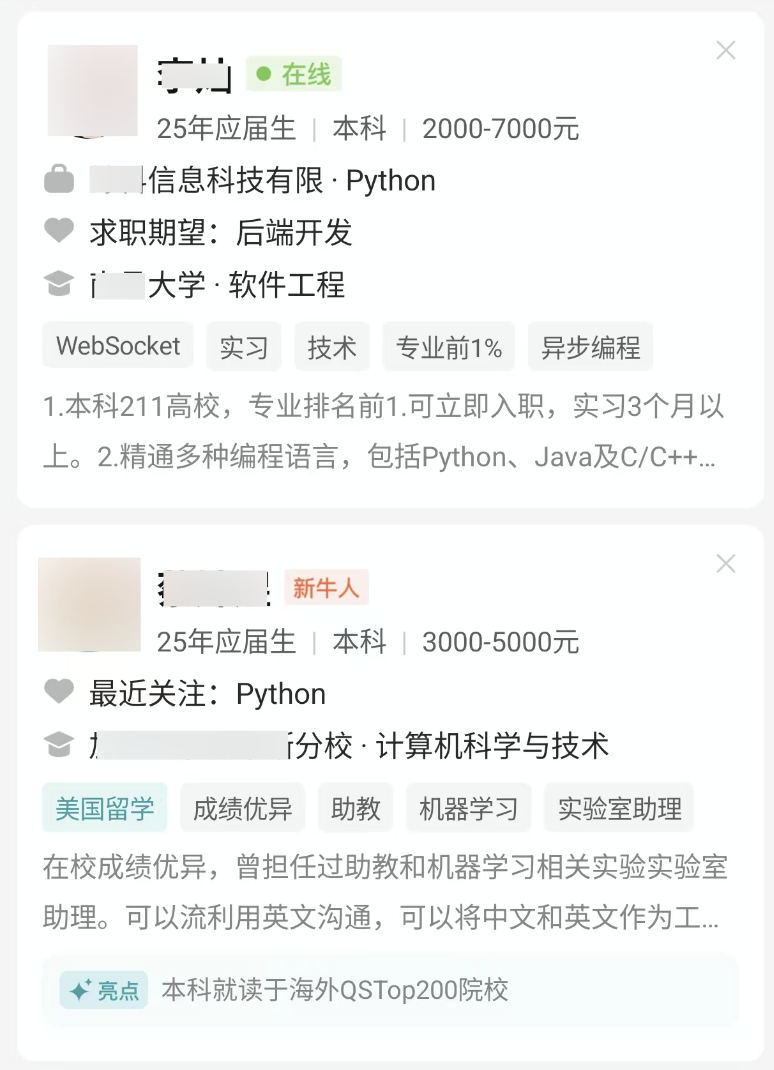
如果你应聘职位是 HR,那么很显然你会优先联系当前在线、新牛人这位,同时也要考虑职位匹配程度。但这是一道考察观察和归纳能力的试题:这些小卡片提供了哪些类别的信息?
在工作中的无数场合,我们都需要这样的能力。比如,如果你在做小红书运营,你常常需要快速从两个相似但浏览量迥异的笔记中,找出流量密码,就需要这样的眼力。
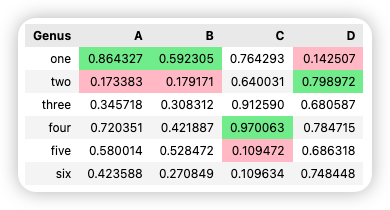
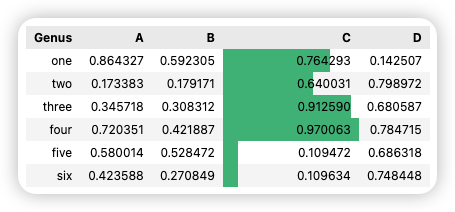
其实这样的能力程序员也非常需要。今天我自己就被将了一军。最终问题定位出来,表现为下图的差异:
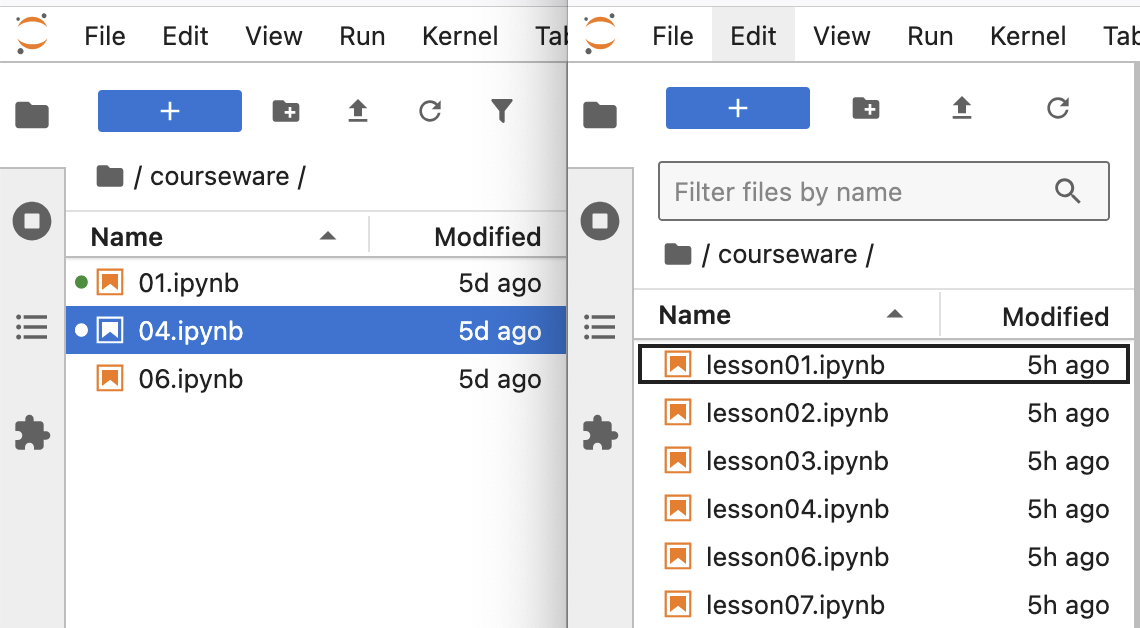
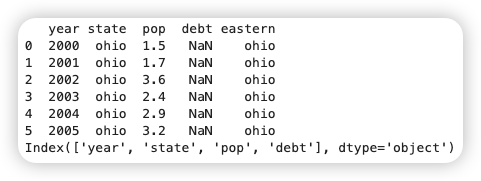
这是我们两门课程的课程目录。它是用 JupyterLab 构建的一个课程环境,当用户点击其中一堂课程时,根据他的权限和购买时长,链接可能打得开也可能打不开。现在的问题是,左边的该打得开的,全都能打开;右边的则全部打不开。
当我们找到最终问题后,把两个目录并排放在一起的时候,可能差异会一目了然。但在编程环境下,不能访问的链接,是以这样的方式出现的:

明明文件就在那儿,没有任何错误,却不能访问。而能访问的链接,还会出一些奇怪的错误来干扰你。
要了解这个问题为什么复杂,我们得先介绍下系统的架构和技术栈。这也是为什么说我们用 Augment 构建了一个复杂项目的原因。通过对比我们的项目,你就会知道,在现在的 AI 能力下,你能构建的项目,至少能复杂到什么程度,这对你决策多大程度投入到AI中会有一定帮助。
系统架构
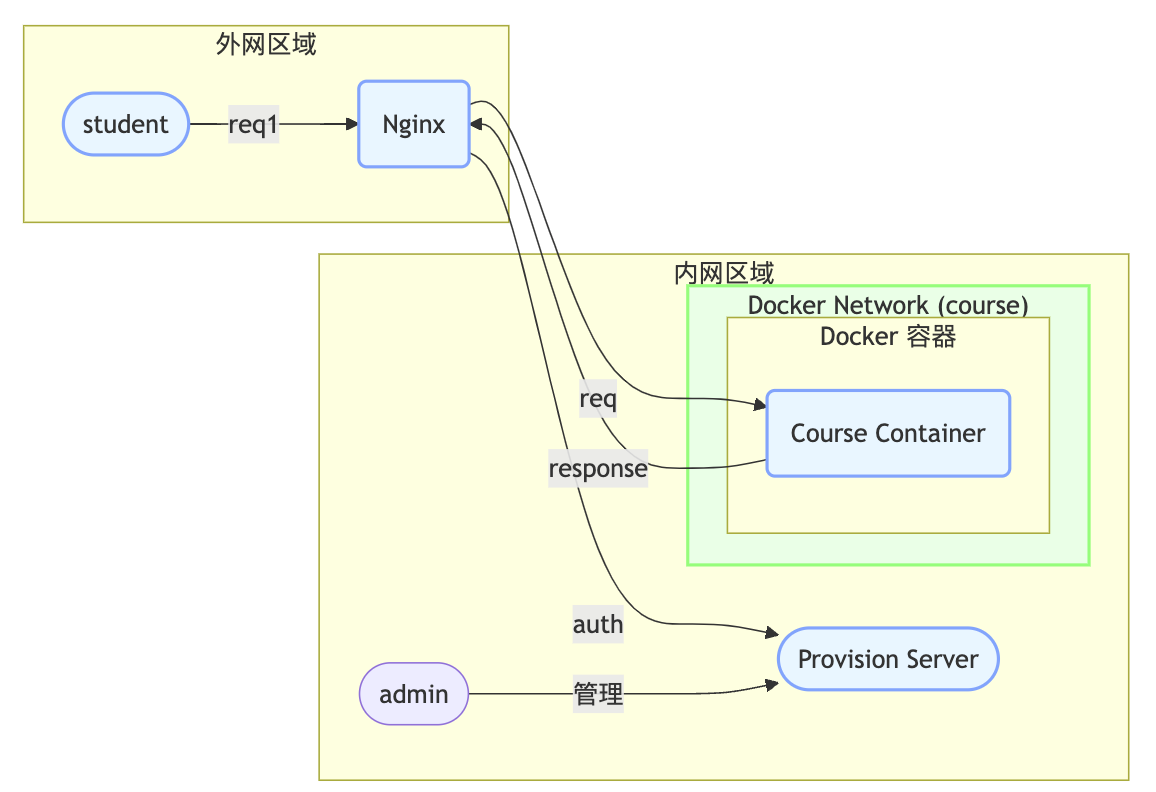
这是一个简化了的系统架构图。限于 AI 生成 mermaid 图的能力,它跟我们实际的架构有一些区别:
- nginx 与 course container 在同一个 docker 网络。nginx 暴露了主机端口。
- nginx 要能访问主机上的 provision server. Provisioin server 只部署在主机中,因为它需要为新学员创建容器。
- 系统中有很多 course container。Nginx 收到浏览器传来的类似 courseware/01.ipynb 这样的请求之后,需要动态地分发到每个学员对应的 course container。该 container 运行在 JupyterLab 的服务。
- 使用了前后端分离式设计,并且有两个前端 SPA,一个由 nginx host,另一个由 provision server 来 host。这会存在两个 front 的目录,而且要和后端 (python) 放在同一个项目中,这种架构并不常见,也为项目开发增加了许多难度。
- 实际部署中还涉及更复杂的云上网络,细节就不透露了。
为了限制未登录用户的访问,每一个请求,都要由 nginx 发给 provision server 来认证。所以,有时候出现前面的不能访问的图,会是正常行为。
这个系统的技术栈和技术要求如下:
- 使用 vue3 和 vite 来构建前端。前端尽可能做到响应式。
- 由于创建容器的时间可能较长,前端的 admin 界面需要与后端有 web socket 通信,把后端容器的构建状态实时传递给前端。这里还用到了多线程。
- 数据库使用文件数据库就好。一般应该选择 sqlite,不过我更熟悉和喜欢 postgreSQL 的语法,因此使用 duckdb。
- Provision 服务器使用了 Blacksheep 来构建,它性能卓越,同时接口很人性化。但是,社区没有 flask 等成熟。最终这个选择让我付出一定的代价。大概有一天多时间用在解决 blacksheep 自身面临的如何 host SPA 程序的问题。这里还有一个有趣的小故事。
- Blacksheep 不能独立运行,它必须借助 uvicorn 来启动。uvicorn 也很不成熟,它贡献了一个小 bug,AI 也不清楚如何解决,查了 github 才找到解决方案。这额外耽误了一天时间。
- 使用了 nginx 的 auth_request 模块,来认证用户。最初还尝试了 openlightspeed,最后撤退到社区更成熟的 nginx 上来。
- 我用的是 mac 开发,最终部署到 ubuntu 上。在 mac 下,我使用 orbstack 来运行容器。它和 nginx 官方容器一起,贡献了一个日志目录映射的 bug。
你们会觉得这个系统复杂吗?我觉得可以算是。因为它用了两种编程语言,还涉及到 docker 和 nginx 一些改写规则,所以,实际上涉及到三名工程师:前端工程师 (Vuejs)、后端工程师 (Python) 和运维工程师的活。
反正,我花 299 报名学的 AI 编程是这样的:
完成这样的项目,只要一个前端就可以了。而且它只有两种固定的界面版式,也没有考虑到PC端。
令人疲惫的下午
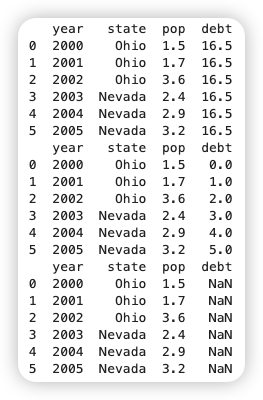
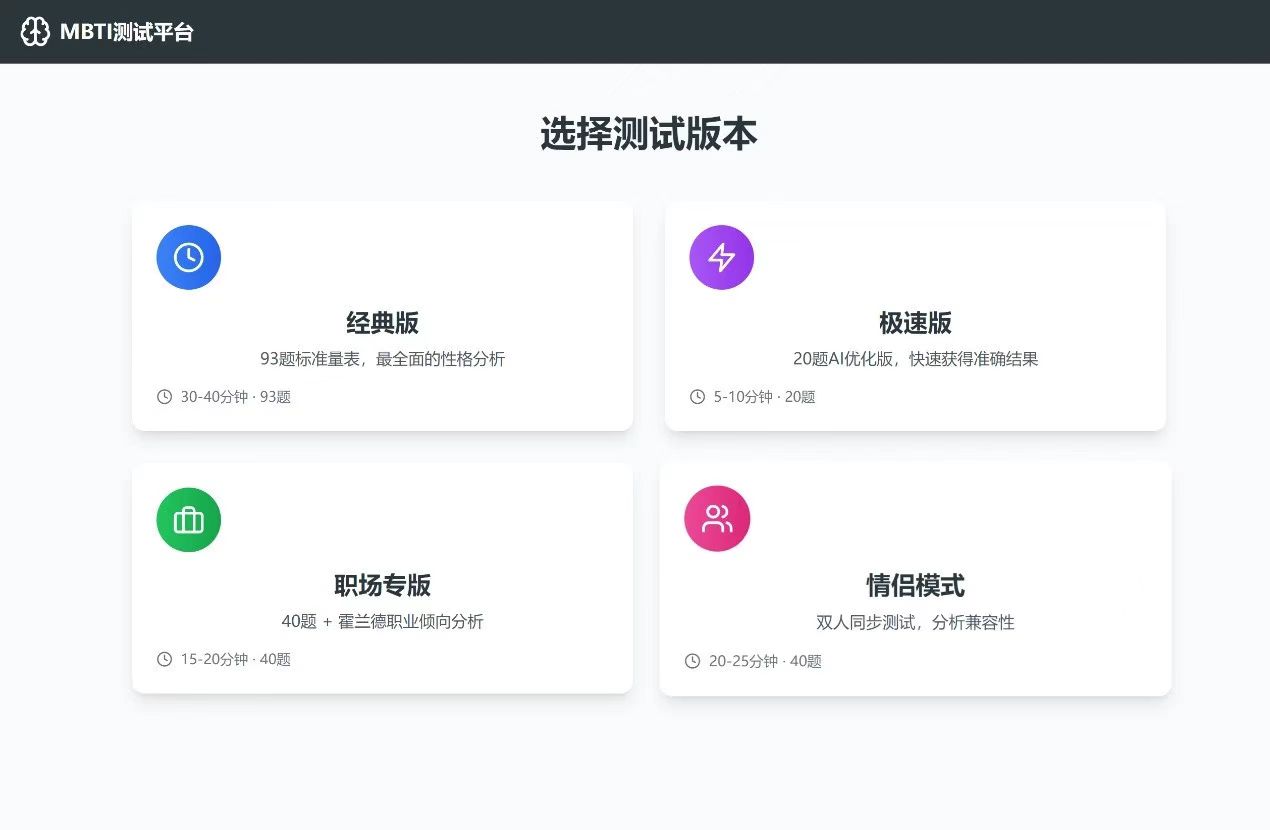
今天下午,我正在为新的课程系统上线,做最后的测试。这个系统本来应该像这样工作,这是添加客户:
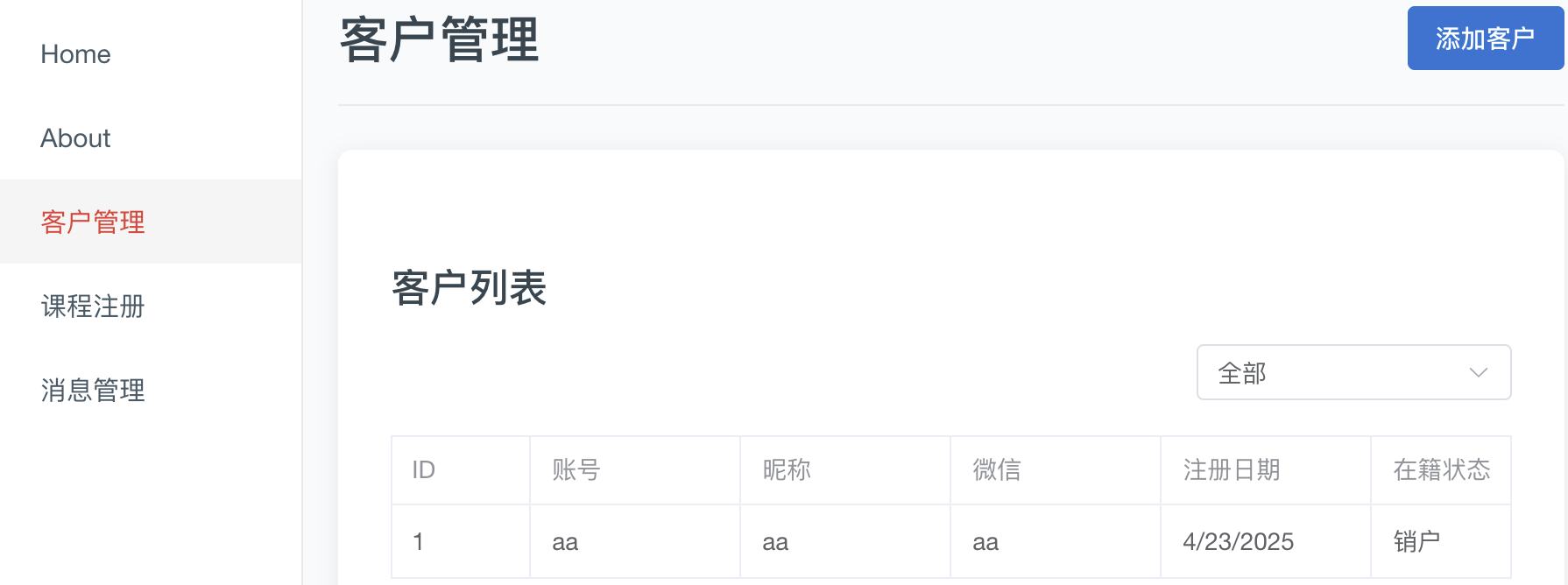
在增加用户之后,就可以为他注册课程,生成专属环境:

然后,学员就可以在浏览器中登录:
登录之后,就可以看到他所报名的课程:
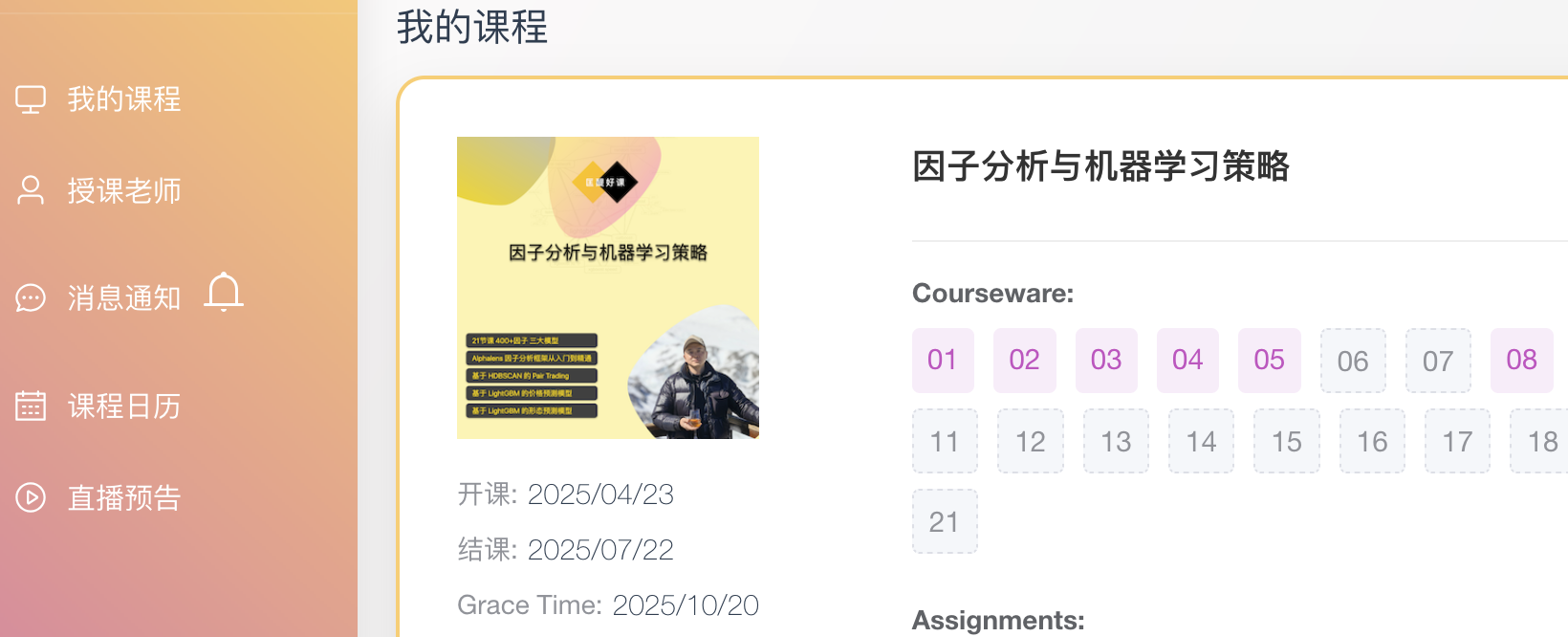
用户点击粉红色的课程链接,就应该看到该课的内容。这个课程的链接是:
1 | |
点击之后,本来应该能打开 01.ipynb 这个 notebook,但实际上返回了不能访问的错误。此时会进入到 jupyter lab 的 home 界面:
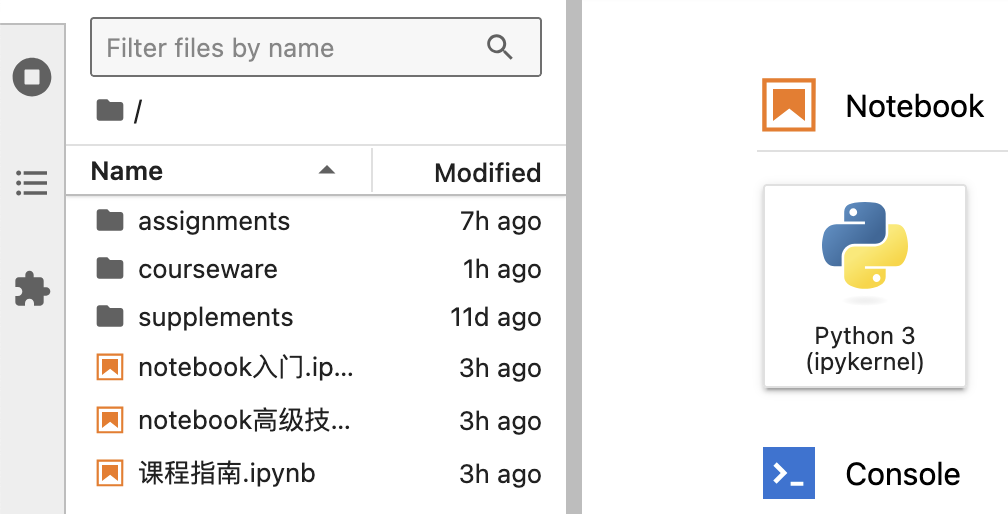
此时清楚地看到所有的 notebook 都已经列出来了,但是当你点击它们时,仍然是不能访问。
由于这个问题只在《量化 24 课》中存在,在《因子分析与机器学习策略》课程中不存在,所以,我肯定这只是一个部署和配置问题,于是,就只开启了 Augment 的 chat 模式来帮我。
它指导了我一下午。我们查过两个容器的 entrypoint 脚本是否一样,目录映射语法是否一样,jupyter_lab_config 是否一样,容器的环境变量是否一样,Augment 还多次兴奋地大喊,我找到问题了!
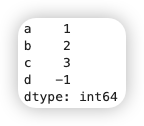
在无数次修改、重启和回滚之后,我想明白一件事,作为出题人,如果我自己来看这张图:
我就能一眼看出上下两个卡片的所有区别吗?我会不会进入到某种常识性的盲区?比如,124 和 l24 用肉眼是很难看出来的,天知道有多少这种细微的差别!
于是,我决定启用 Augment 的 Agent (Auto) 模式。实际上这些天的大多数时间,我是在用 Agent Auto 来帮我 coding 的。
Tip
Augment 有三种模式,chat, agent 和 agent auto 模式。Chat 模式一样能读全部代码,写代码(和修改),但它不能调用工具;Agent 模式可以做 Chat 能做的事,并且可以调用工具,但在调用工具之前,需要得到你的批准;Agent Auto 模式则非常高效,它会自动调用工具,直到最后告诉你,很好!我已经完成了这个任务。
但是,我不想让 Agent Auto 在最后关头给我任何惊喜,所以,我告诉他,
Attention
在我们正在工作的项目中,存在这样一个问题。当我点击 academy > 我的课程面板 > 24 课的链接时出现无法访问;但 fa 课程的链接就可以访问。两者都是经过同一个 nginx 容器转发;nginx 后面的容器不一样,一个是 course_l24_quantide,一个是 course_fa_quantide.
我启用 agent 模式,不是让你进行改动,而是让你可以直接运行一些命令来查看文件和(包括容器)状态。
现在,请着手调查这个问题。
Aha 时刻
Agent 以常规的姿势开始,先是响应我的问题。但我的问题说得比较笼统,所以,它的响应也很简单:
1 | |
老实说,有点没太指望了。
接下来,它阅读了 containers.yaml -- 这是用来创建容器的配置文件。
然后它调用 docker ps 检查哪些容器正在运行。它了解到 nginx 容器很重要,于是,把 nginx 看了个底掉:
1 2 3 4 | |
在调查阶段,它没有出任何结论,而是接着看另外两个容器:
1 2 | |
它还调查了这几个容器是否都连接在同一个 course 网络:
1 | |
然后再检查这两个容器中,jupyter 是否在运行(这个动作有点没有必要,如果是人工来做,这样做会累死驴)
1 2 | |
然后它检查了 notebook 文件名:
1 2 | |
这些都平平无奇。接下来就是比较智能的地方了,它开始怀疑 url 与文件名不匹配!
1 | |
运行的这个命令我是有点看不懂了,果然是编程奇才。
然后又看了一遍文件名:
1 | |
然后又回过头去,查看我们提供给用户的链接:
1 | |
把这么多信息匹配起来,显然是很费脑的事情,但 Augment 正是在人困马乏之际,发现了问题所在:
Tip
我们提供给用户的链接是 /courseware/01.ipynb,但 01.ipynb 在 24 课中并不存在;在 24 课中,存在的是 lesson01.ipynb。这是一个典型的部署问题。在因子课中,所有的文件名都只有序号,但在 24 课中,源文件画蛇添足地带上了 lesson 的前缀。
作为一个人类,我确实不容易发现这个问题,作为课程的开发者,对我来说,01.ipynb 和 lesson01.ipynb都是第一课。这也是 AI 给我上的又一课。
结论
我听到过很多关于AI编程能力很弱的问题。但用过Augment之后,我觉得事实并非如此,懂得如何运用它更为重要。
实际上,我是从2023年7月的Github Copilot用起的。当时的copilot可以很好地完成文字润色和编造单元测试数据的任务,它记得很多经典算法的精巧代码结构。后来较长时间使用通义灵码,短暂使用过 Trae (国际版)和Cursor。同样是使用 Claude 3.7模型,但我感觉Augment的能力是最强的(Augment团队认为他们用的是Claude 3.7+O1的一个集成训练版,并不是简单的Claude 3.7)。另外,则于在推广期,所以使用人数少也是一大优势 -- 它的响应速度比较快。
今天我们揭示了它的一个用法,即限制住Augment的Agent,不让它生成代码,而是让它像一个资深专家一样,深入到各个子系统,在主机与dockder容器网络之间来回穿梭,去排查一些很微不足道,但如果你不掌握系统的全部运行原理,就无法排查的问题。
如果你认为我们的provision系统有一定复杂度和实用性,也苦恼过Augment或者其它AI工具无法构建复杂应用,可以给我留言,如果有较多读者认为这些经验值得分享,我就再来写一篇。