当我们使用 Jupyter 时,很显然我们的主要目的是探索数据。这篇文章将介绍如何利用 JupySQL 来进行数据查询--甚至代替你正在使用的 Navicat, dbeaver 或者 pgAdmin。此外,我们还将介绍如何更敏捷地探索数据,相信这些工具,可以帮你省下 90%的 coding 时间。
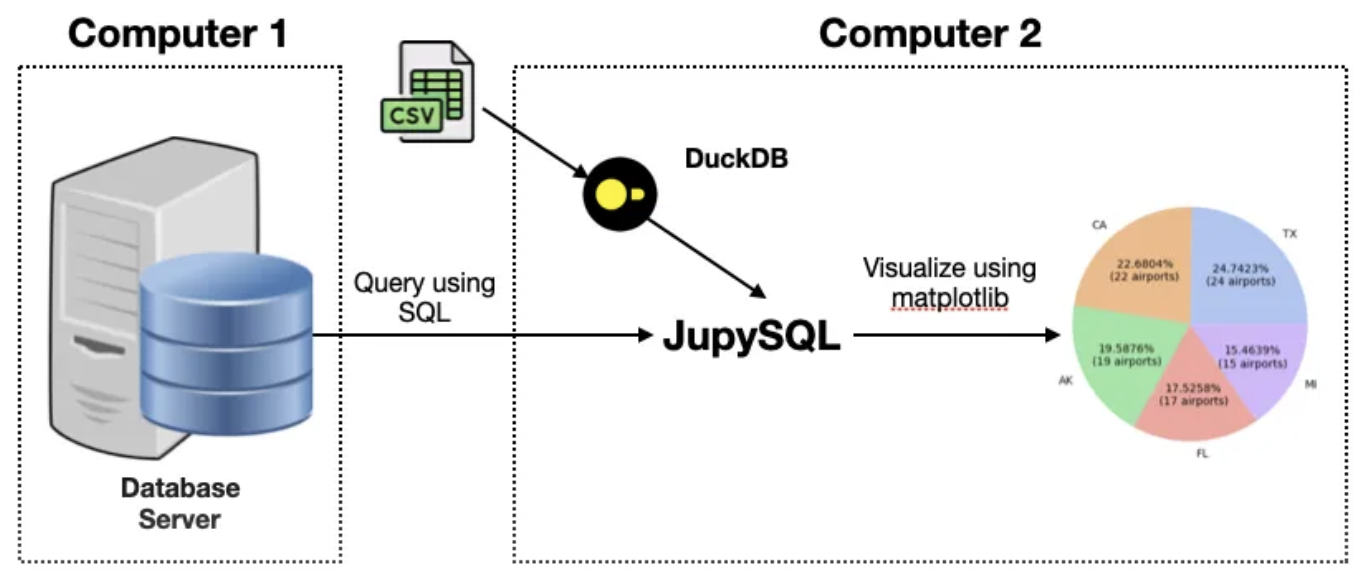
JupySQL 是一个运行在 Jupyter 中的 sql 查询工具。它支持传统关系型数据库(PostgreSQL, MySQL, SQL server)、列数据库(ClickHouse),数据仓库 (Snowflake, BigQuery, Redshift, etc) 和嵌入式数据库 (SQLite, DuckDB) 的查询。
之前我们不得不为每一种数据库寻找合适的查询工具,找到开源、免费又好用的其实并不容易。有一些工具,设置还比较复杂,比如像 Tabix,这是 ClickHouse 有一款开源查询工具,基于 web 界面的。尽管它看起来简单到甚至无须安装,但实际上这种新的概念,导致一开始会引起一定的认知困难。在有了 JupySQL 之后,我们就可以仅仅利用我们已知的概念,比如数据库连接串,SQL 语句来操作这一切。
除了查询支持之外,JupySQL 的另一特色,就是自带部分可视化功能。这对我们快速探索数据特性提供了方便。
现在,打开一个 notebook,执行以下命令,安装 JupySQL:
| %pip install jupysql duckdb-engine --quiet
|
之前你可能是这样使用 pip:
在前一篇我们学习了 Jupyter 魔法之后,现在你知道了,%pip 是一个 line magic。
显然,JupySQL 要连接某种数据库,就必须有该数据库的驱动。接下来的例子要使用 DuckDB,所以,我们安装了 duckdb-engine。
Info
DuckDB 是一个性能极其强悍、有着现代 SQL 语法特色的嵌入式数据库。从测试上看,它可以轻松管理 500GB 以内的数据,并提供与任何商业数据库同样的性能。
在安装完成后,需要重启该 kernel。
JupySQL 是作为一个扩展出现的。要使用它,我们要先用 Jupyter 魔法把它加载进来,然后通过%sql 魔法来执行 sql 语句:
| %load_ext sql
# 连接 DUCKDB。下面的连接串表明我们将使用内存数据库
%sql duckdb://
# 这一行的输出结果为 1,表明 JUPYSQL 正常工作了
%sql select 1
|
不过,我们来点有料的。我们从 baostock.com 上下载一个 A 股历史估值的示例文件。这个文件是 Excel 格式,我们使用 pandas 来将其读入为 DataFrame,然后进行查询:
| import pandas as pd
df = pd.read_excel("/data/.common/valuation.xlsx")
%load_ext sql
# 创建一个内存数据库实例
%sql duckdb://
# 我们将这个 DATAFRAME 存入到 DUCKDB 中
%sql --persist df
|
现在,我们来看看,数据库里有哪些表,表里都有哪些字段:
| # 列出数据库中有哪些表
%sqlcmd tables
# 列出表'DF'有哪些列
%sqlcmd columns -t df
|
最后一行命令将输出以下结果:
| name |
type |
nullable |
default |
autoincrement |
comment |
| index |
BIGINT |
True |
None |
False |
None |
| date |
VARCHAR |
True |
None |
False |
None |
| code |
VARCHAR |
True |
None |
False |
None |
| close |
DOUBLE PRECISION |
True |
None |
False |
None |
| peTTM |
DOUBLE PRECISION |
True |
None |
False |
None |
| pbMRQ |
DOUBLE PRECISION |
True |
None |
False |
None |
| psTTM |
DOUBLE PRECISION |
True |
None |
False |
None |
| pcfNcfTTM |
DOUBLE PRECISION |
True |
None |
False |
None |
作为数据分析师,或者量化研究员,这些命令基本上满足了我们常用的 DDL 功能需求。在使用 pgAdmin 的过程中,要找到一个表格,需要沿着 servers > server > databases > database > Schema > public > Tables 这条路径,一路展开所有的结点才能列出我们想要查询的表格,不免有些烦琐。JupySQL 的命令简单多了。
现在,我们预览一下这张表格:
| %sql select * from df limit 5
|
我们将得到如下输出:
| index |
date |
code |
close |
peTTM |
pbMRQ |
psTTM |
pcfNcfTTM |
| 0 |
2022-09-01 |
sh.600000 |
7.23 |
3.978631 |
0.370617 |
1.103792 |
1.103792 |
| 1 |
2022-09-02 |
sh.600000 |
7.21 |
3.967625 |
0.369592 |
1.100739 |
1.100739 |
| 2 |
2022-09-05 |
sh.600000 |
7.26 |
3.99514 |
0.372155 |
1.108372 |
1.108372 |
| 3 |
2022-09-06 |
sh.600000 |
7.26 |
3.99514 |
0.372155 |
1.108372 |
1.108372 |
| 4 |
2022-09-07 |
sh.600000 |
7.22 |
3.973128 |
0.370105 |
1.102266 |
1.102266 |
%sql 是一种 line magic。我们还可以使用 cell magic,来构建更复杂的语句:
| # EXAMPLE-1
%%sql --save agg_pe
select code, min(peTTM), max(peTTM), mean(peTTM)
from df
group by code
|
使用 cell magic 语法,整个单元格都会当成 sql 语句,这也使得我们构建复杂的查询语句时,可以更好地格式化它。这里在%%sql 之后,我们还使用了选项 --save agg_pe,目的是为了把这个较为复杂、但可能比较常用的查询语句保存起来,后面我们就可以再次使用它。
Tip
在 JupySQL 安装后,还会在工具栏出现一个 Format SQL 的按钮。如果一个单元格包含 sql 语句,点击它之后,它将对 sql 语句进行格式化,并且语法高亮显示。
我们通过 %sqlcmd snippets 来查询保存过的查询语句:
这将列出我们保存过的所有查询语句,刚刚保存的 agg_pe 也在其中。接下来,我们就可以通过%sqlcmd 来使用这个片段:
| query = %sqlcmd snippets agg_pe
# 这将打印出我们刚刚保存的查询片段
print(query)
# 这将执行我们保存的代码片段
%sql {{query}}
|
最终将输出与 example-1 一样的结果。很难说有哪一种数据库管理工具会比这里的操作来得更简单!
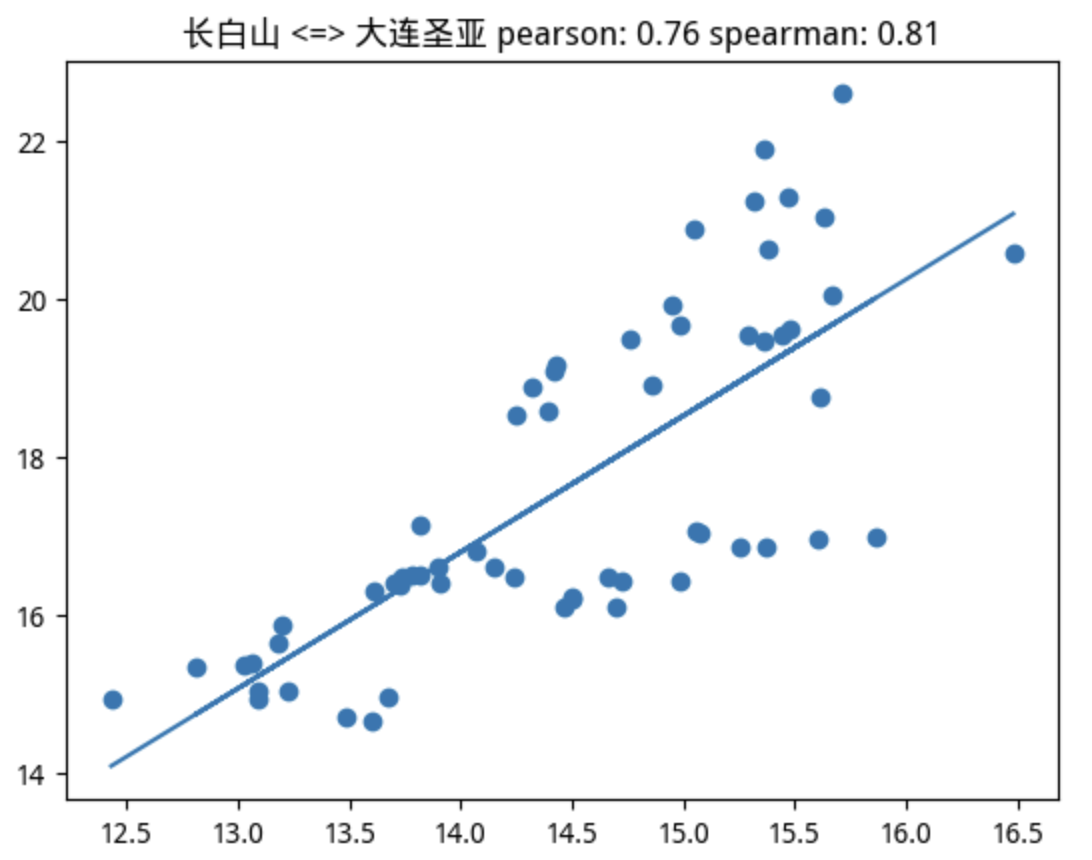
JupySQL 还提供了一些简单的绘图,以帮助我们探索数据的分布特性。
| %sqlplot histogram -t df -c peTTM pbMRQ
|
JupySQL 提供了 box, bar, pie 和 histogram。
不过,JupyerSQL提供的可视化功能并不够强大,只能算是中杯。有一些专业工具,它们以pandas DataFrame为数据载体,集成了数据修改、筛选、分析和可视化功能。这一类工具有, Qgrid(来自 Quantpian),PandasGUI,D-Tale 和 mitosheet。其中D-Tale功能之全,岂止是趣大杯,甚至可以说是水桶杯。
我们首先探讨的是Qgrid,毕竟出自Quantpian之手,按理说他们可能会加入量化研究员最常用的一些分析功能。 他们在 Youtube 上提供了一个 presentation,介绍了如何使用 Qgrid 来探索数据的边界。不过,随着 QuantPian 关张大吉,所有这些工具都不再有人维护,因此我们也不重点介绍了。
PandasGUI 在 notebook 中启动,但它的界面是通过 Qt 来绘制的,因此,启动以后,它会有自己的专属界面,而且是以独立的 app 来运行。它似乎要求电脑是 Windows。
Mitosheet的界面非常美观。安装完成后,需要重启 jupyterlab/notebook server。仅仅重启 kernel 是不行的,因为为涉及到界面的修改。
重启后,在Notebook的工具条栏,会多出一个“New Mitosheet”的按钮,点击它,就会新增一个单元格,其内容为:
| import mitosheet
mitosheet.sheet(analysis_to_replay="id-sjmynxdlon")
|
并且自动运行这个单元格,调出 mito 的界面。下面是 mitto 中可视化一例:
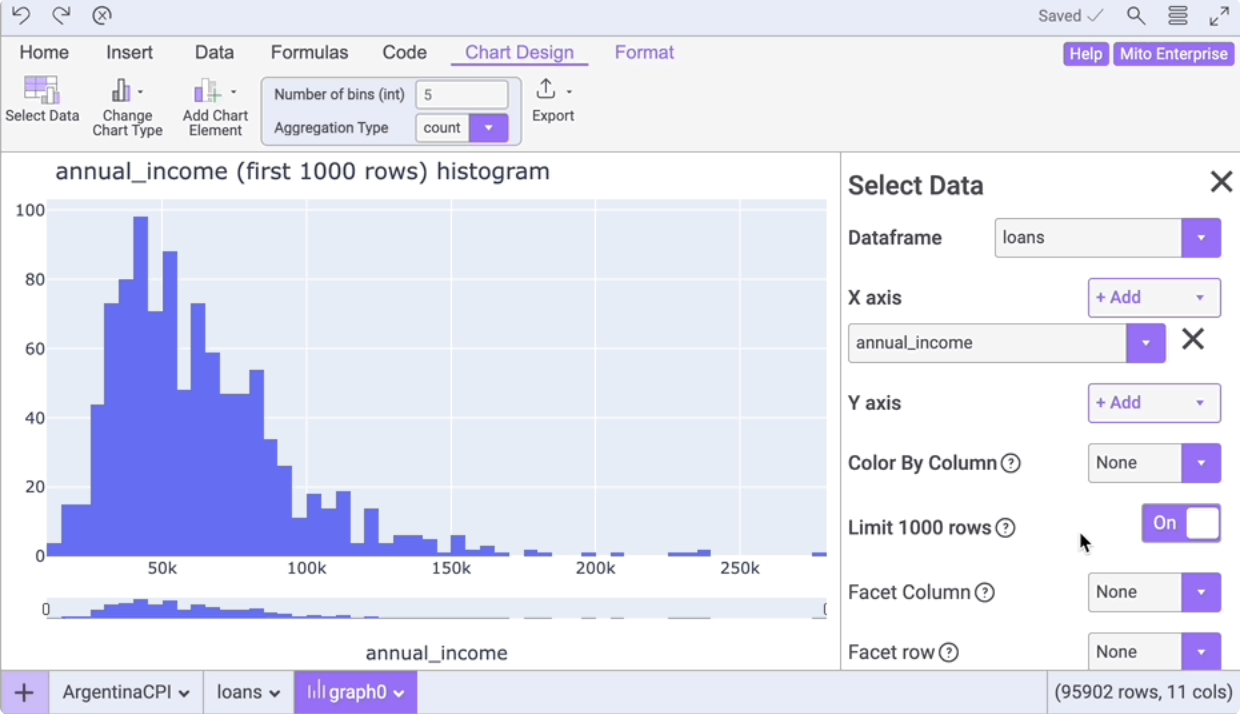
mitto 有免费版和专业版的区分,而且似乎它会把数据上传到服务器上进行分析,所以在国内使用起来,感觉不是特别流畅。
与上面介绍的工具相比,D-Tale 似乎没有这些工具有的这些短板。
我们在 notebook 中通过pip install dtale来安装 dtale。安装后,重启 kernel。然后执行:
| import dtale
dtale.show(df)
|
这会显加载以下界面:
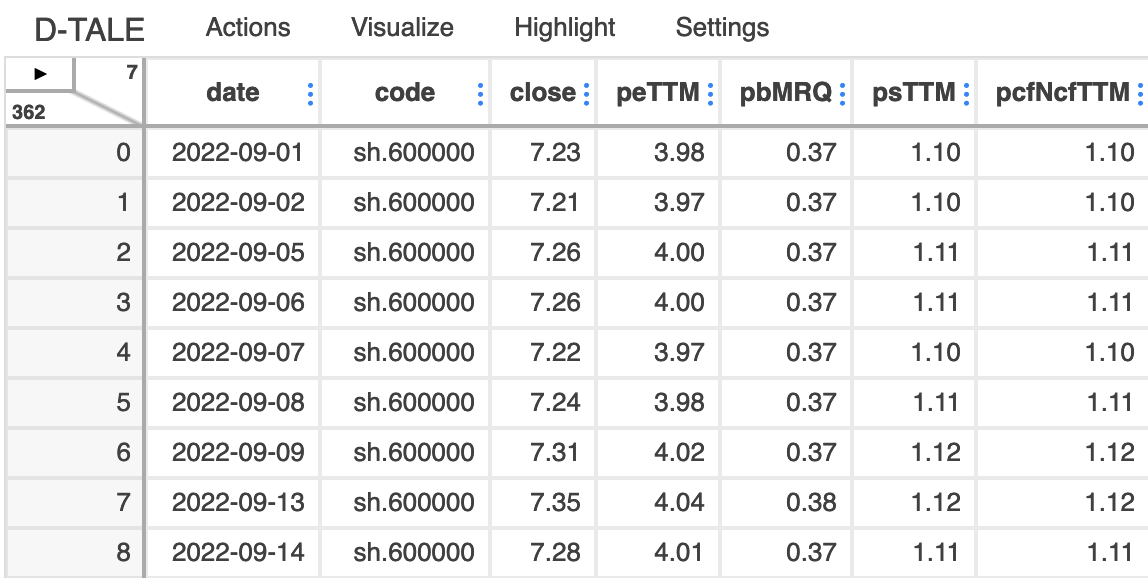
在左上角有一个小三角箭头,点击它会显示菜单:
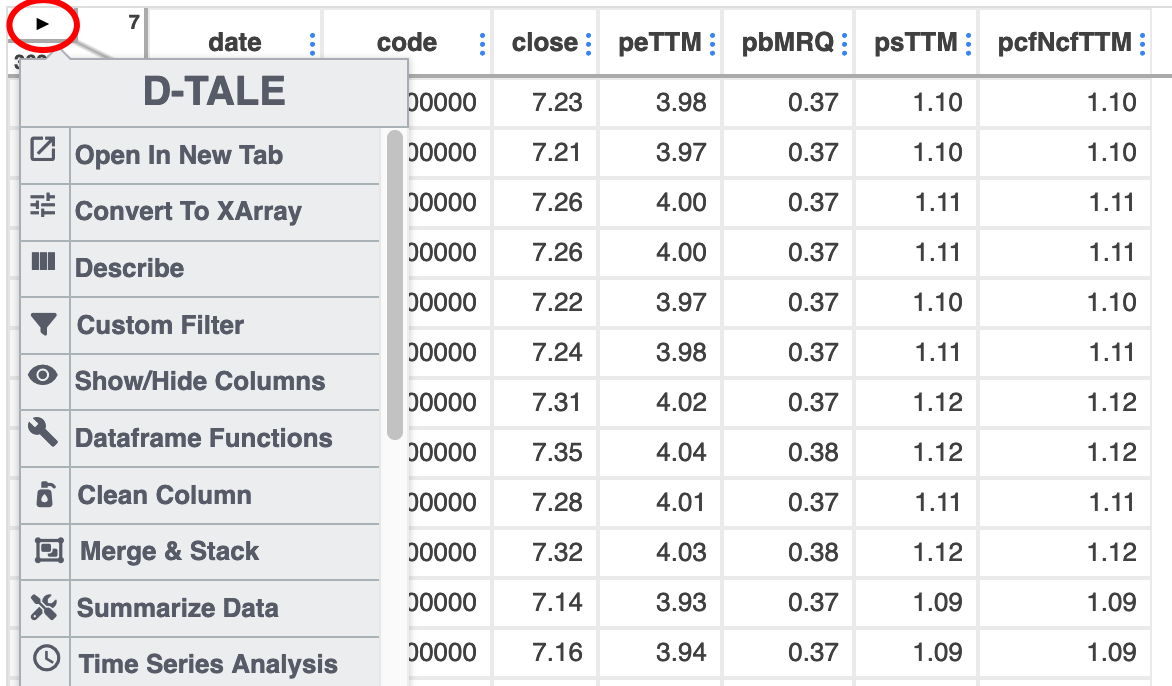
我们点击describe菜单项看看,它的功能要比df.describe 强大不少。df.describe 只能给出均值、4 分位数值,方差,最大最小值,dtale 还能给出 diff, outlier, kurtosis, skew,绘制直方图,Q-Q 图(检查是否正态分布)。
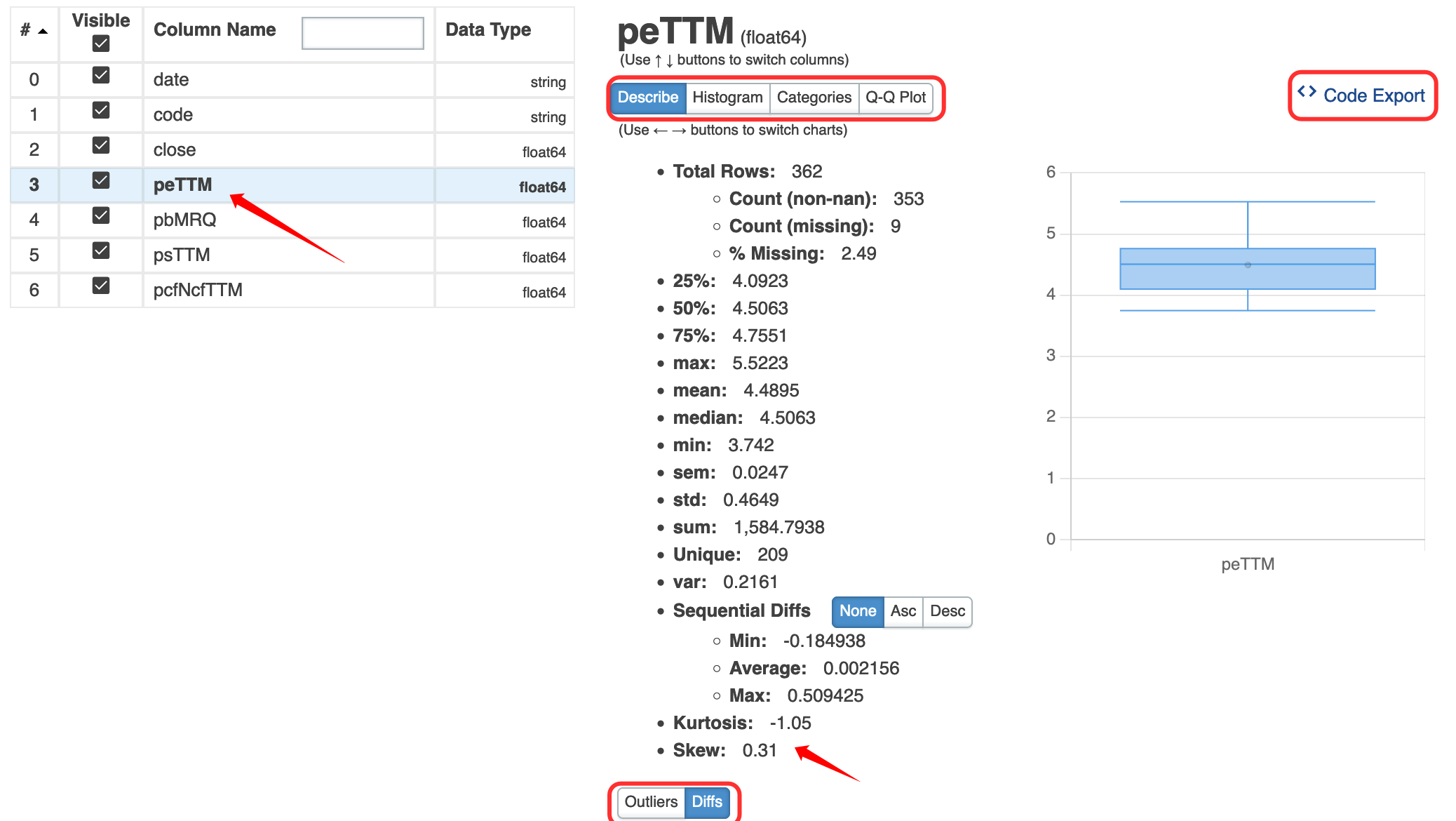
注意我们可以导出进行这些计算所用的代码!这对数据分析的初学者确实很友好。
这是从中导出的绘制 qq 图的代码:
| # DISCLAIMER: 'DF' REFERS TO THE DATA YOU PASSED IN WHEN CALLING 'DTALE.SHOW'
import numpy as np
import pandas as pd
import plotly.graph_objs as go
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | if isinstance(df, (pd.DatetimeIndex, pd.MultiIndex)):
df = df.to_frame(index=False)
# REMOVE ANY PRE-EXISTING INDICES FOR EASE OF USE IN THE D-TALE CODE, BUT THIS IS NOT REQUIRED
df = df.reset_index().drop('index', axis=1, errors='ignore')
df.columns = [str(c) for c in df.columns] # update columns to strings in case they are numbers
s = df[~pd.isnull(df['peTTM'])]['peTTM']
import scipy.stats as sts
import plotly.express as px
qq_x, qq_y = sts.probplot(s, dist="norm", fit=False)
chart = px.scatter(x=qq_x, y=qq_y, trendline='ols', trendline_color_override='red')
figure = go.Figure(data=chart, layout=go.Layout({
'legend': {'orientation': 'h'}, 'title': {'text': 'peTTM QQ Plot'}
}))
|
有了这个功能,如果不知道如何通过 plotly 来绘制某一种图,那么就可以把数据加载到 dtale,用 dtale 绘制出来,再导出代码。作为量化人,可能最难绘制的图就是 K 线图了。这个功能,dtale 有。
最后,实际上dtale是自带服务器的。我们并不一定要在 notebook 中使用它。安装 dtale 之后,可以在命令行下运行dtale命令,然后再打开浏览器窗口就可以了。更详细的介绍,可以看这份 中文文档。

 作者David Hsieh 出生于香港,是Duke大学教授,在对冲基金和另类beta上有着深入而广泛的研究。William Fung则是伦敦商学院对冲基金教育研究中心的客座教授。
作者David Hsieh 出生于香港,是Duke大学教授,在对冲基金和另类beta上有着深入而广泛的研究。William Fung则是伦敦商学院对冲基金教育研究中心的客座教授。