机器的觉醒!人工智能风云激荡70年
机器学习是人工智能的一个子集。人工智能是指使计算机系统能够执行通常需要人类智能才能完成的任务的技术和方法。人工智能涵盖了多种技术和子领域,如机器学习、深度学习、自然语言处理、计算机视觉、专家系统等。
人工智能的概念正式提出是在1956年达特矛斯的夏季人工智能研究会上。达特矛斯学院(Dartmouth College)虽小,但却是常春藤大学之一。这次会议由约翰·麦卡锡发起,克劳德.香农等人参与了研讨会。约翰·麦卡锡是计算机科学家和认知科学家,也是人工智能学科的创始人之一。他还是著名的编程语言Lisp的发明者,早期许多人工智能系统和算法都是用Lisp语言编写的。
 达特茅斯AI研讨会
达特茅斯AI研讨会
发起会议的约翰·麦卡锡最初认为,只要集中全美最好的几位科学家,大概只要8周就能攻克人工智能问题。不想从1956年发起的宏伟梦想,经过近70年的筚路褴褛,今天仍然只能算是半道其中。
这一路上,就像是光的微粒说与波动说的争论一样,关于人工智能的发展方向,也一直存在两种主要的思想,即人工智能应该基于规则还是基于数据来构建模型?两种思想之间的争斗跌宕起伏,最终在三位华人科学家的加持下,数据派占据了上风,同时铸就了当代人工智能波澜壮阔的发展。
人工智能最先从仿生学得到启发。1890年代,Santiago Ramón Cajal(圣地亚哥·拉蒙·卡哈尔)提出了神经元学说,后来被Camillo Golgi(Camillo Golgi)通过高尔基染色法所证实。1943年,Warren MeCulloch(沃伦.麦卡洛克)和Walter Pitts(沃尔特.皮茨)将复杂的神经元电化学过程简化为相对简单的信号交换[^activation],最终为人工智能仿生打下坚实的基础。
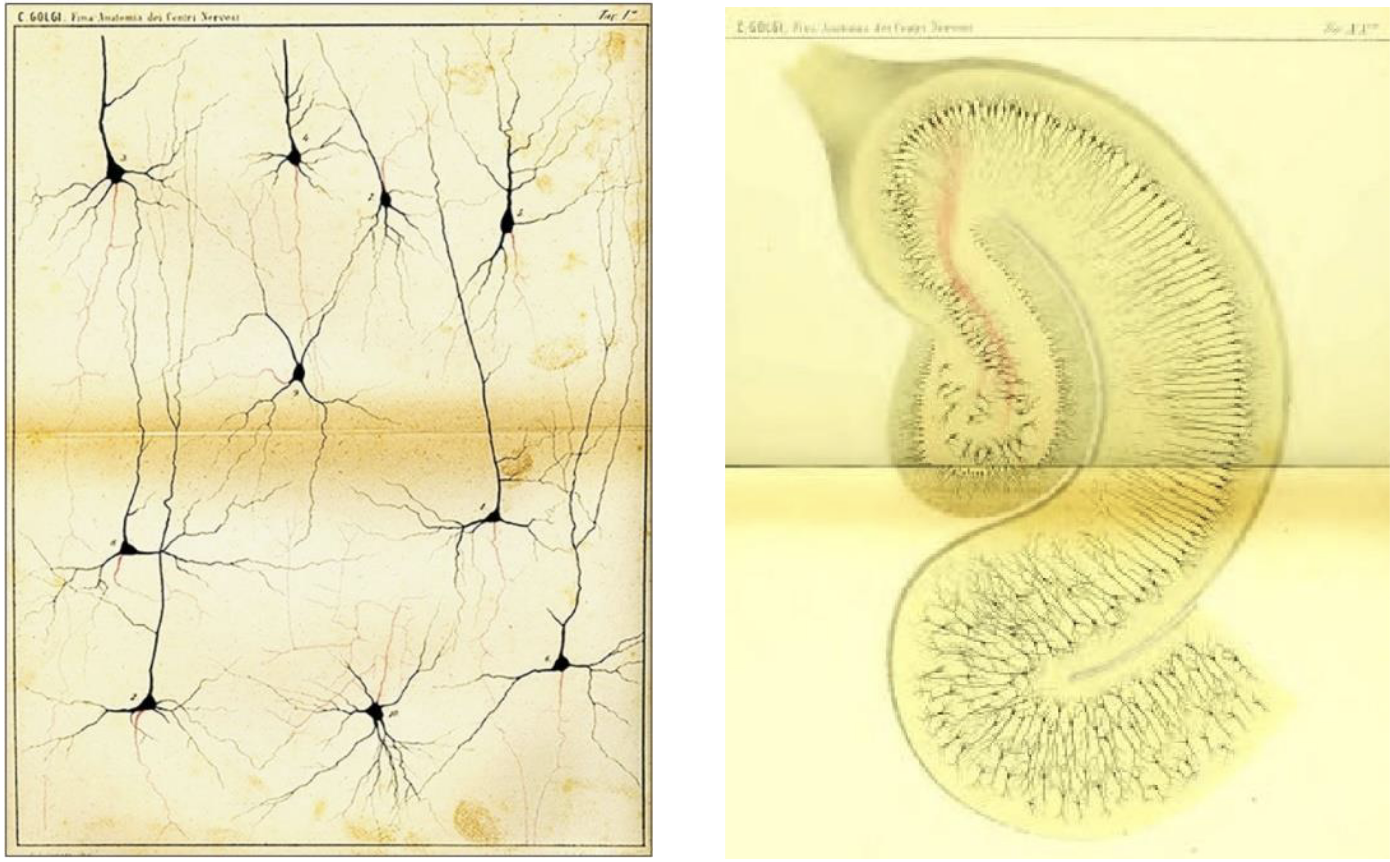 高尔基染色和海马体
高尔基染色和海马体
1958年,Frank Rosenblatt(弗兰克·罗森布拉特)根据仿生学原理,提出了感知机(Perceptron),这是最早的神经网格模型之一,感知机能够通过学习线性分类器来解决二分类问题。Rosenblatt的感知机是个天才的发明,因为当时的计算技术还没有数字化,Rosenblatt训练感知机的过程,都是靠手动切换开关完成的。尽管很原始,但通过训练,感知机最终获得了形状识别的可靠能力。
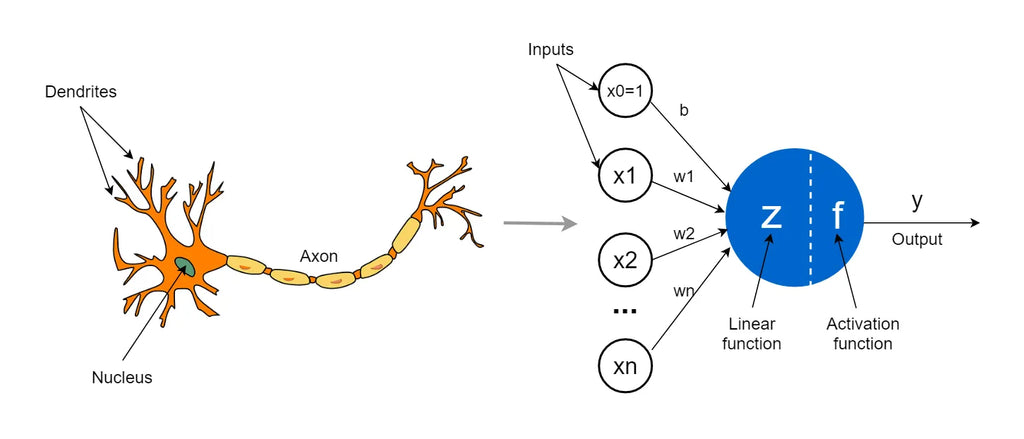 感知机示意图
感知机示意图
感知机一度被誉为重大的技术进步。但这一发明过于超前,世界还未为它的诞生做好准备 -- 直到50年以后,人们才明白,神经网络需要数字化输入输出设备、大量的算力和存储,而最终还需要海量的数据。毕竟,人脑有超过1000亿个神经元组成,在1958年,人类只能模拟大脑容量的几亿分之一。
因此,感知机带来的热浪仅持续不到一年,就受到猛烈的攻击。其中最大的反对者,正是达特矛斯AI研讨会的发起人之一马文.明斯基,和另一位数学家、计算机科学的先驱 -- 西摩.佩珀特。他们在1969年出版了一本名为《感知机》的书,抨击感知机缺乏严谨的理论基础 -- 实际上直到今天,人工智能仍然不能为自己找到坚实的数学基石,在很多时候,它的行为仍然是一个黑盒子 -- 这一点倒是很像大脑。
感知机是基于数据的机器学习模型。在感知机遭到重创之后,机器学习阵线不得不沉寂十多年之久。而在此期间,知识工程与专家系统则占据了风头。其中最有名的,可能是一个名为内科医生-I的程序,它的数据库中包含了500种疾病描述和3000种疾病表现。但是,由于现实世界太复杂,基于规则的模型能够很好地处理检索,但在推理上就显得呆板而肤浅,并且规则越多,就越难相容,于是很快也败下阵来。
专家系统是当年人类实现人工智能最后的希望。因此,专家系统的落败,也导致人工智能的发展陷入低谷,进入了冰冻的寒武纪。然而,正如地球经历寒武纪一样,在封冻的冰层之下,进化正在加速,一些革命性的突破,即将到来。
 Geoffrey Hinton 2024年诺贝尔物理学奖
Geoffrey Hinton 2024年诺贝尔物理学奖
1986年,杰弗里·辛顿[^hinton](Geoffrey Hinton)、大卫·鲁梅尔哈特(David Rumelhart)和罗恩·威廉姆斯(Ron Williams)发表了反向传播算法。这是深度学习的奠基之作,它使得多层神经网络的训练成为可能,从理论上,我们向模拟有1000亿神经元的大脑迈出了至关重要的一步。但深度学习的时代并没有立刻到来,人工智能还被封印在厚厚的冰雪之下。
又过去了10多年。1998年,Yann LeCun(杨立昆)提出了LeNet,这是最早的卷积神经网络,也是人类历史上第一个有实际用途的神经网络。它被广泛应用于全美的自动提款机上,用来读取支票上的数字。Yann LeCun的成功再次掀起了人工智能浪潮,也最终把机器学习路线重新带回到人们的视野中来。
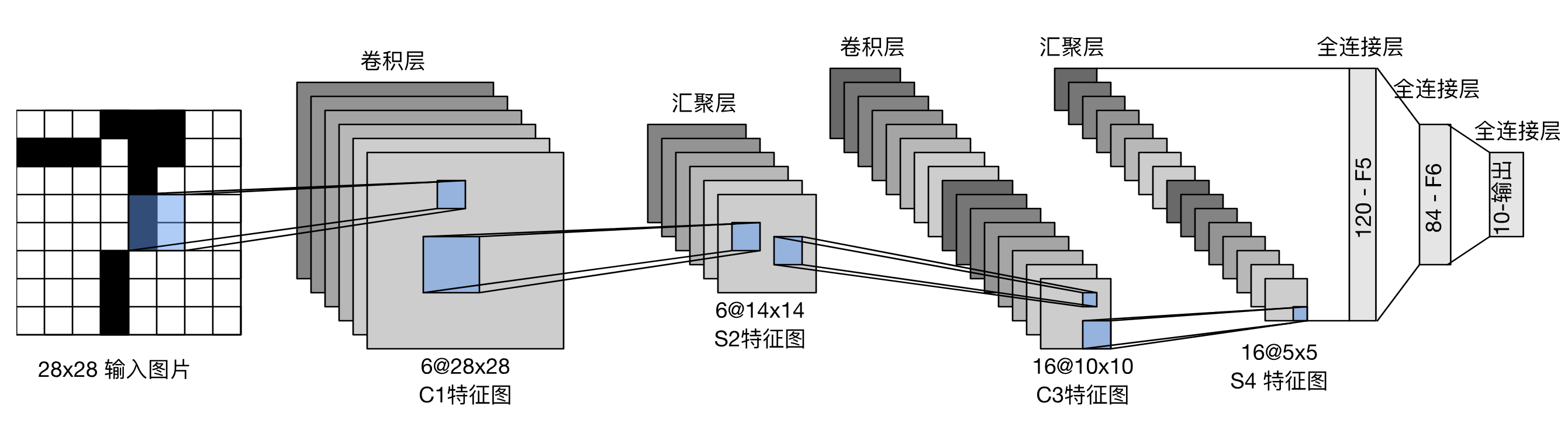 LeNet, by Yann LeCun
LeNet, by Yann LeCun
不过,Yann LeCun的成功还无法产生势如破竹、摧枯拉朽般的攻势。相反地,在短暂的热闹之后,人工智能的研究似乎再次进入休眠期。不过,这一次它只是小憩了4年,很快,它将被AlexNet唤醒,随后便如河出伏流,一泄千里。
而在这次复苏的背后,两位华人科学家--黄仁勋和李飞飞则是最重要的幕后英雄。前者以英伟达的显卡和Cuda引擎为深度学习提供了强大的算力,后者则以ImageNet数据集,为卷积神经网络提供了土壤和营养。
Info
 李飞飞
李飞飞
李飞飞正是当代的第谷。
AlexNet也是一个卷积神经网络,它由Alex Krizhevsky, Ilya Sutskever和Geoffrey Hinton提出,在2012年的ImageNet竞赛中,取得了85%的识别准确率,比上一届的冠军整整提升了10%!LeNet只能运用在一个很小的场景下,处理很小规模的数据集,而AlexNet则是在超过1000个分类的图片上进行的识别,它的成功显然更具现实意义和突破性。AlexNet让基于数据驱动的机器学习路线加冕成为王者。直到今天,尽管机器学习还存在种种不足,我们离通用人工智能还不知道有多长的距离,但是,似乎再也没有声音质疑机器学习,而要改用基于规则的专家系统了。
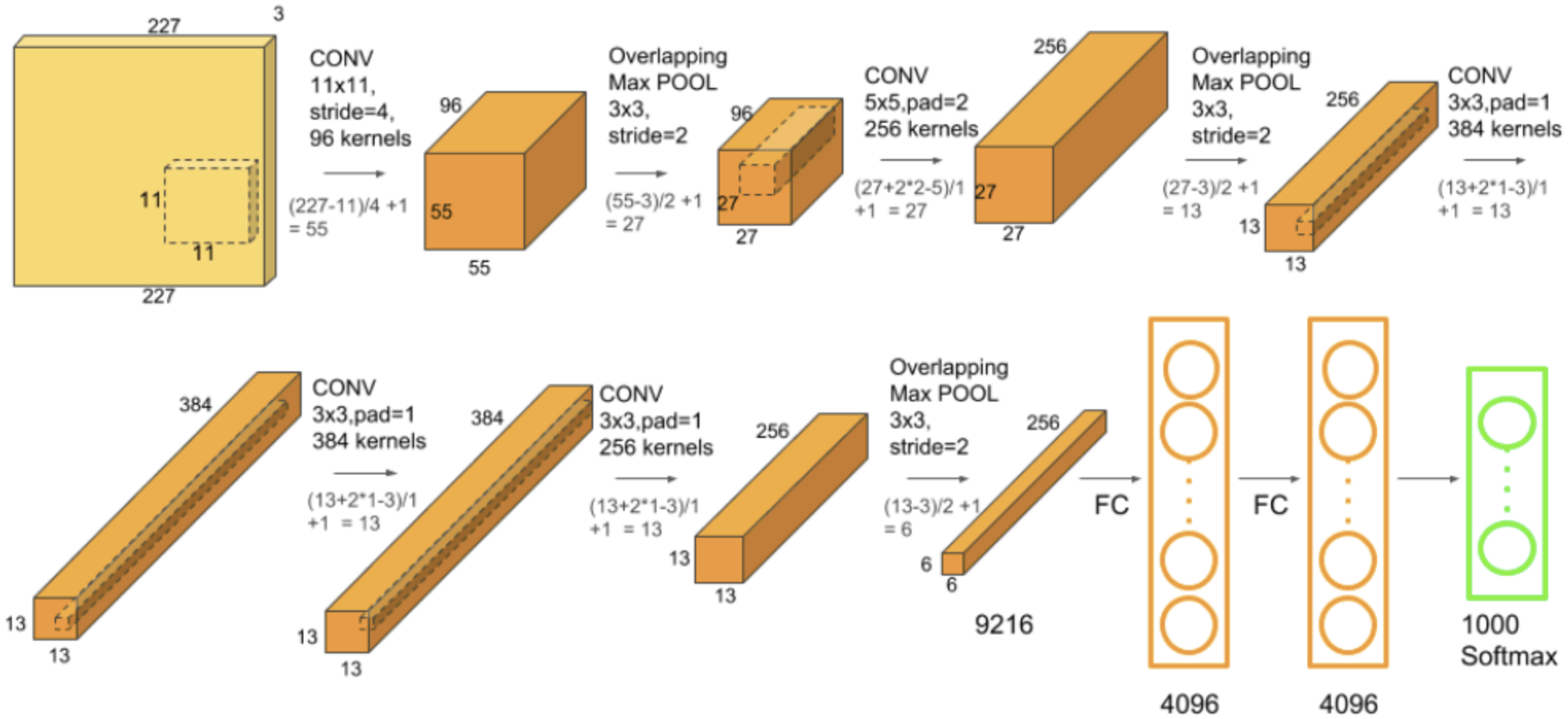 AlexNet
AlexNet
下一个突破则是机器视觉对人类的超越。根据研究,在ImageNet数据集上人类的分类能力极限是5.1%的错误率。一旦机器视觉的错误率低于这个指标,也就战胜了人类,意味着人工智能在视觉上的应用完全成熟。
这个决定性的胜利是由华人科学家何明恺在2016年取得的。他通过深度残差网络,将神经网络的层数增加到了惊人的(与当时的水平相比)152层,但通过巧妙的设计,允许输入数据在训练阶段绕过其中的某些层,从而部分解决了深层网络中的梯度消失问题。
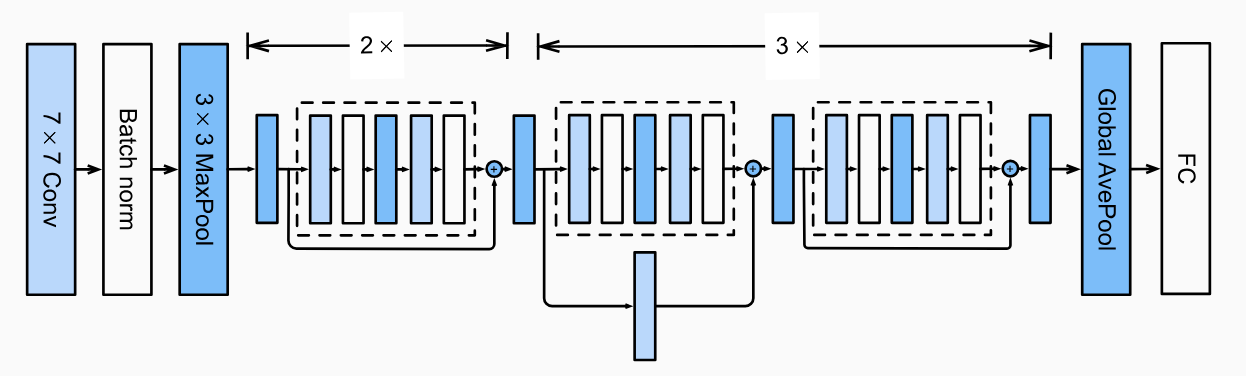 ResNet-18
ResNet-18
最终,resnet在识别错误率降到了4.5%,显著地超越了人类的极限!再也没有任何理由怀疑和拒绝人工智能的应用了!
到此为止,机器学习路线取得了压倒性的胜利,人工智能研究就进入加速时代。在短短的几年后,甚至自然语言理解也被突破,以transformer为代表的架构在自然语言理解、文生图、文生视频、编程等多个领域都取得了成功。
行百里者半九十。人类的终极愿景 -- 通用人工智能(AGI)何时能产生还未可知。人工智能在未来应该成为人类的伴侣,但此刻,人类的亚当还没能造出自己的夏娃。此外,尽管当代人工智能模型已经极为强大,但它内部的运行机制仍然没有坚实的理论基础,AI引起的伦理问题才刚刚暴露,这些都是未来有待我们攻克的一道道关卡。